📝 Paper Summary
Multilingual Text Embedding
Zero-shot Transfer Learning
LUSIFER adapts English-centric LLM embedding models for multilingual tasks by bridging them with a multilingual encoder via a lightweight connector, enabling zero-shot transfer without multilingual supervision.
Core Problem
State-of-the-art LLM-based embedding models are predominantly English-centric, suffering significant performance degradation in medium and low-resource languages due to a lack of multilingual training data.
Why it matters:
- Current English-centric models create a disparity in capabilities, leaving low-resource languages behind in critical tasks like retrieval and RAG.
- Existing multilingual solutions typically require expensive, explicit multilingual supervision (translation data or multilingual finetuning), which is often unavailable for many languages.
- Simply using multilingual BERT-style models (like XLM-R) misses out on the superior semantic reasoning and representational capacity of modern Large Language Models.
Concrete Example:
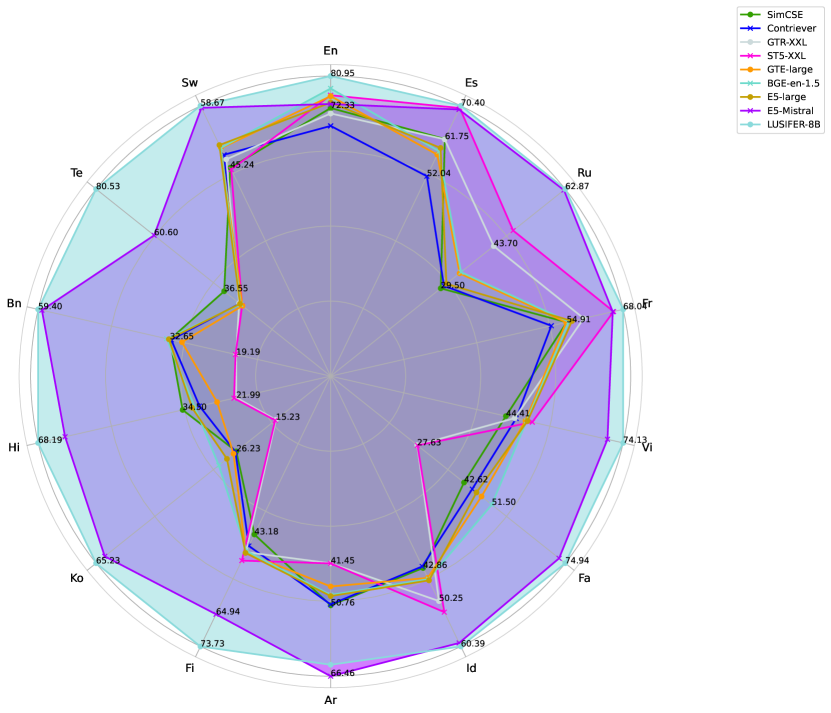
In Telugu (a low-resource language), the English-centric E5-Mistral model achieves a score of roughly 40 (implied from the +22.15 gain). By aligning XLM-R with Mistral, LUSIFER raises this to over 60 without seeing Telugu data during alignment training.
Key Novelty
Universal Multilingual Connector for LLMs (LUSIFER)
- Combines a frozen multilingual encoder (XLM-R) with an English-centric LLM (Mistral) using a lightweight 'connector' module (MLP + learnable token).
- Treats the multilingual encoder as a universal translator that maps diverse languages into a shared semantic space, which the connector then projects into the LLM's English input space.
- Enables the target LLM to 'understand' foreign languages zero-shot by processing their aligned representations as if they were familiar English semantics.
Architecture
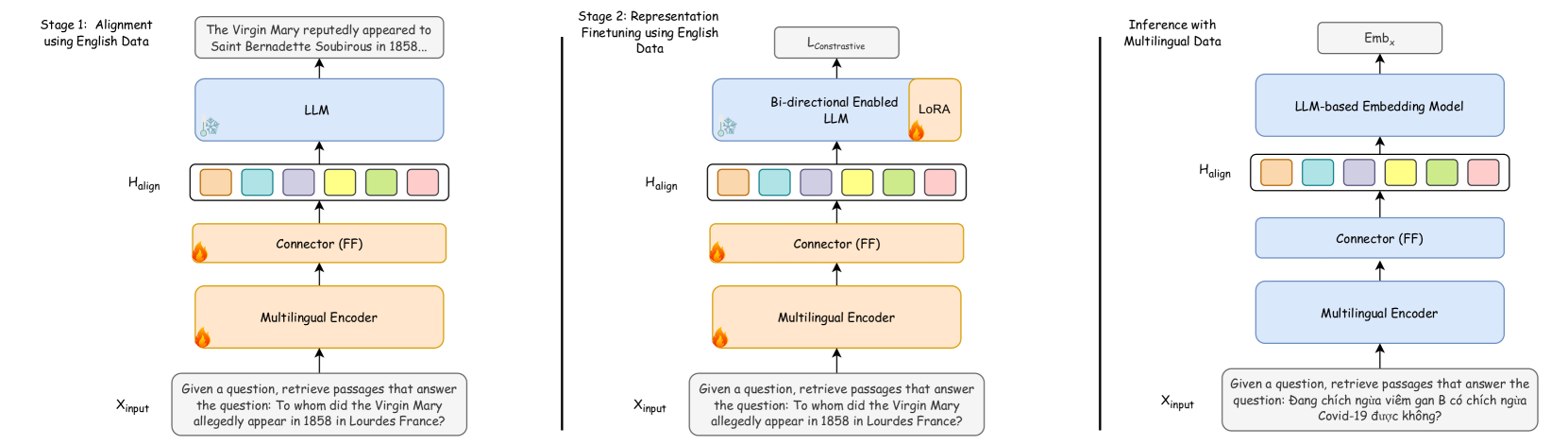
The LUSIFER architecture connecting a Multilingual Encoder to a Target LLM via a Connector module.
Evaluation Highlights
- Outperforms E5-Mistral by +3.19 points on average across 14 languages on a new comprehensive benchmark of 123 datasets.
- Achieves massive gains in low-resource languages, such as a +22.15 point improvement over E5-Mistral on Telugu embedding tasks.
- Surpasses E5-Mistral by +5.75 points on average across 5 cross-lingual retrieval datasets covering over 100 languages.
Breakthrough Assessment
8/10
Offers a highly efficient zero-shot solution for multilingualizing LLMs. The gain in low-resource settings (+22 points) is remarkable, though it relies on existing multilingual encoders like XLM-R.