📝 Paper Summary
Scientific Reasoning
Post-training Datasets
Instruction Tuning
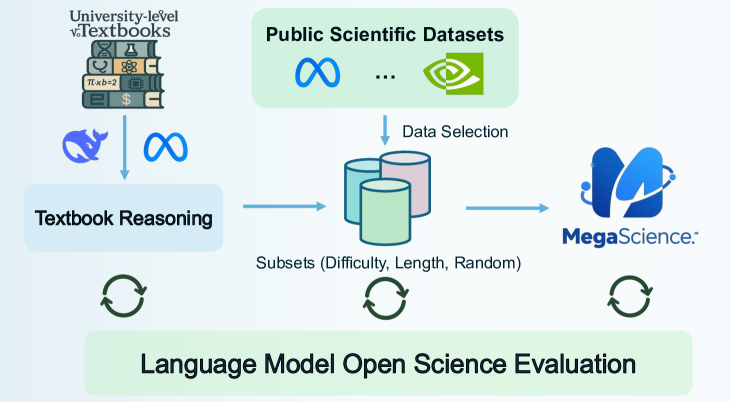
The paper introduces TextbookReasoning and MegaScience, two large-scale, high-quality scientific reasoning datasets curated from textbooks and optimized public data, which enable base models to outperform official instruct models.
Core Problem
Existing open-source scientific reasoning resources are underdeveloped compared to math/coding, suffering from unreliable benchmarks, weak decontamination, low-quality web-scraped answers, and superficial distillation that promotes overthinking.
Why it matters:
- Current benchmarks often use multiple-choice formats that inflate performance scores without reflecting true computational reasoning ability
- Existing decontamination (n-gram overlap) is fragile, leading to significant benchmark leakage in post-training datasets
- Distilling long Chain-of-Thought data from models like DeepSeek-R1 often leads to 'overthinking' and inefficiently long responses for simple scientific queries
Concrete Example:
Models trained on existing multiple-choice datasets (e.g., Nemotron-Science) exhibit inflated performance on multiple-choice evaluations but struggle significantly with computational tasks, showing a disconnect between benchmark scores and actual reasoning.
Key Novelty
Dual-Source Curation with Difficulty-Based Selection
- Extracts 650k questions directly from 12k university textbooks (TextbookReasoning) using a dual-standard pipeline to ensure truthful, expert-written reference answers rather than relying solely on potentially hallucinatory LLM generations
- Constructs a massive mixture (MegaScience) by applying specific selection strategies—keeping all textbook data while filtering public datasets via difficulty scoring and response length—to maximize training efficiency
Architecture
The data curation pipeline for TextbookReasoning, detailing the flow from PDF collection to final decontaminated dataset.
Evaluation Highlights
- MegaScience-trained Qwen2.5-7B outperforms the official Qwen2.5-7B-Instruct by +5.2 average score across 15 scientific benchmarks
- MegaScience-trained Llama-3.1-8B surpasses the official Llama-3.1-8B-Instruct by +5.1 average score
- Models trained on MegaScience generate responses with significantly fewer tokens (721 tokens) compared to distillation baselines like NaturalReasoning (1,155 tokens) while achieving better performance
Breakthrough Assessment
8/10
Significant contribution to the under-served scientific domain. The move away from pure web-scraping to textbook extraction and the rigorous decontamination pipeline addresses major reliability issues in current science AI.