📝 Paper Summary
Model Compression
Efficient Inference
This paper presents the first systematic evaluation of quantization on diffusion-based language models, identifying that they exhibit massive activation outliers and recommending rotation-based methods for effective low-bit compression.
Core Problem
Diffusion LLMs (dLLMs) are computationally heavy, but standard quantization techniques used for autoregressive models fail to preserve performance due to unique, massive activation outliers in dLLMs.
Why it matters:
- Diffusion LLMs offer better generation control than autoregressive models but require significantly more memory and compute, hindering deployment on edge devices
- Standard low-bit quantization methods (like SmoothQuant) cause catastrophic performance collapse in dLLMs, necessitating a specialized analysis of which methods actually work
- The behavior of quantization on non-autoregressive, iterative denoising architectures was previously unexplored
Concrete Example:
When quantizing the LLaDA-8B model to 4-bit weights and activations (W4A4) using SmoothQuant, the accuracy on general tasks drops by over 20% due to inability to handle outliers, whereas rotation-based methods like DuQuant maintain usability.
Key Novelty
Systematic Benchmarking of PTQ on dLLMs
- Identifies that dLLMs (like LLaDA and Dream) possess 'massive outliers' in activations—specifically in the second linear layer of Feed-Forward Networks—that are broader than those in autoregressive LLMs
- Demonstrates that rotation-based quantization (transforming the activation space to smooth out spikes) is essential for dLLMs, as simple scaling methods fail under 4-bit settings
Architecture
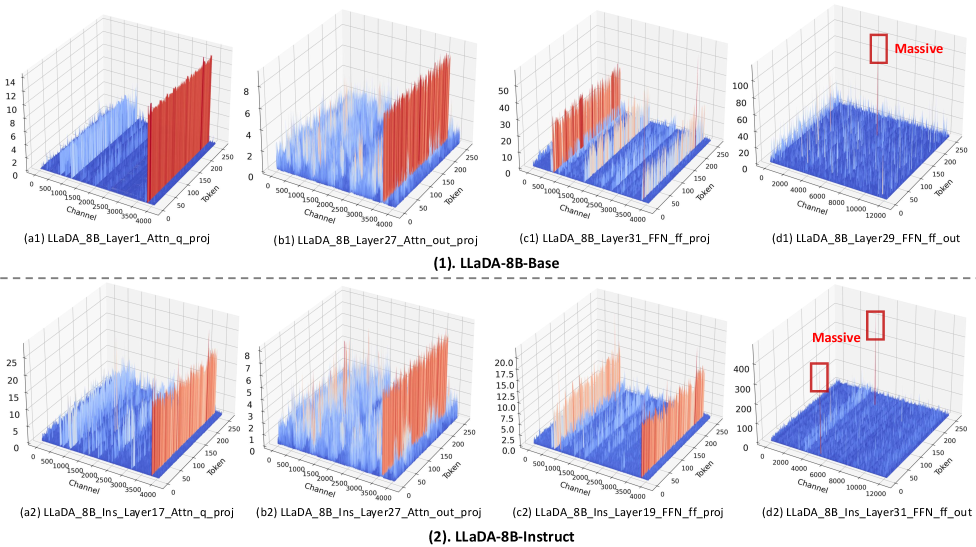
Visualization of activation outliers in LLaDA and Dream models across different layers
Evaluation Highlights
- 4-bit weight-only quantization (GPTQ) is near-lossless on LLaDA-8B-Instruct, improving general QA accuracy from 65.7% to 66.0% (+0.3%)
- Rotation-based method DuQuant outperforms SmoothQuant significantly in W4A4 settings, limiting degradation to ~5% on QA tasks where SmoothQuant suffers >20% drops
- Math and Code tasks are highly sensitive: even robust methods drop >10% accuracy on HumanEval under W4A4, highlighting a remaining challenge for the field
Breakthrough Assessment
7/10
Crucial foundational study establishing baselines and failure modes for dLLM quantization. While it applies existing methods rather than inventing a new one, the discovery of dLLM-specific outlier patterns is highly valuable.