📝 Paper Summary
Real-time video generation
Interactive video generation
Adversarial training for diffusion
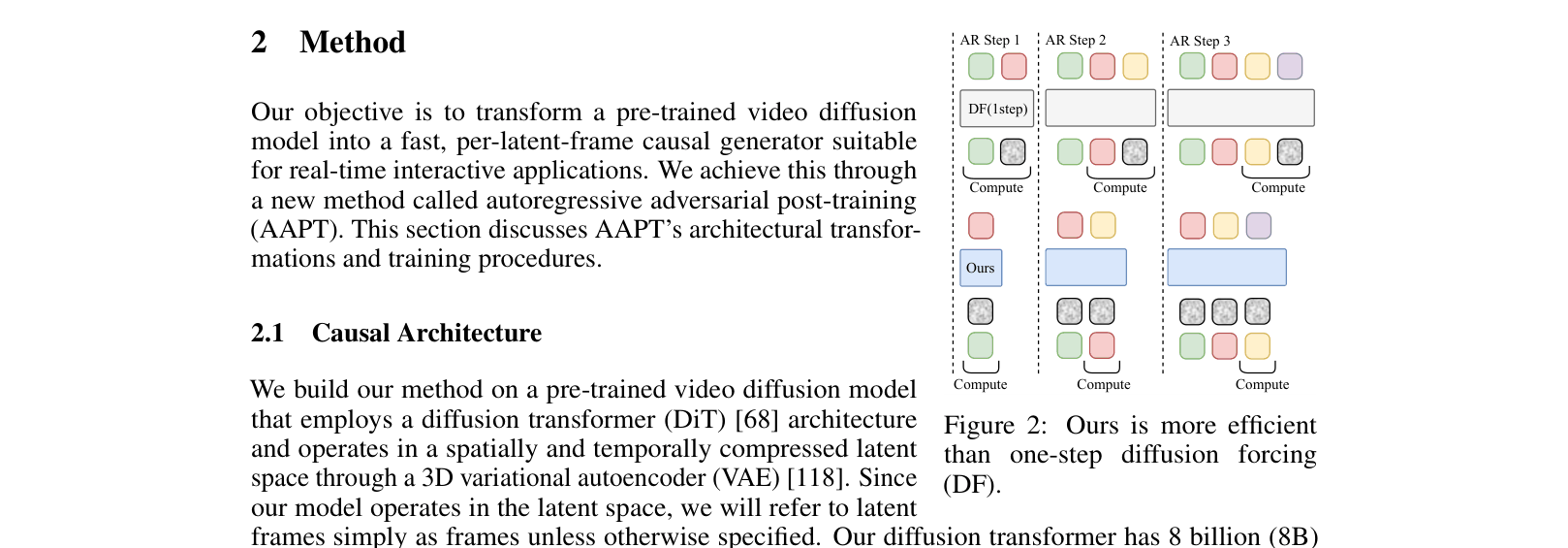
AAPT transforms a pre-trained bidirectional video diffusion model into a causal autoregressive generator that produces one latent frame per step in real-time using adversarial student-forcing.
Core Problem
Existing large-scale video diffusion models are too computationally intensive for real-time interactive applications and suffer from error accumulation when generating long streams.
Why it matters:
- Real-time interaction (e.g., gaming, virtual humans) requires extremely low latency (high FPS) that standard multi-step diffusion cannot meet
- Autoregressive generation often drifts over time due to exposure bias (training with ground truth but generating with predicted history)
- Current fast methods like step distillation or diffusion forcing still require heavy computation (re-processing context) or fail to maintain quality over minute-long durations
Concrete Example:
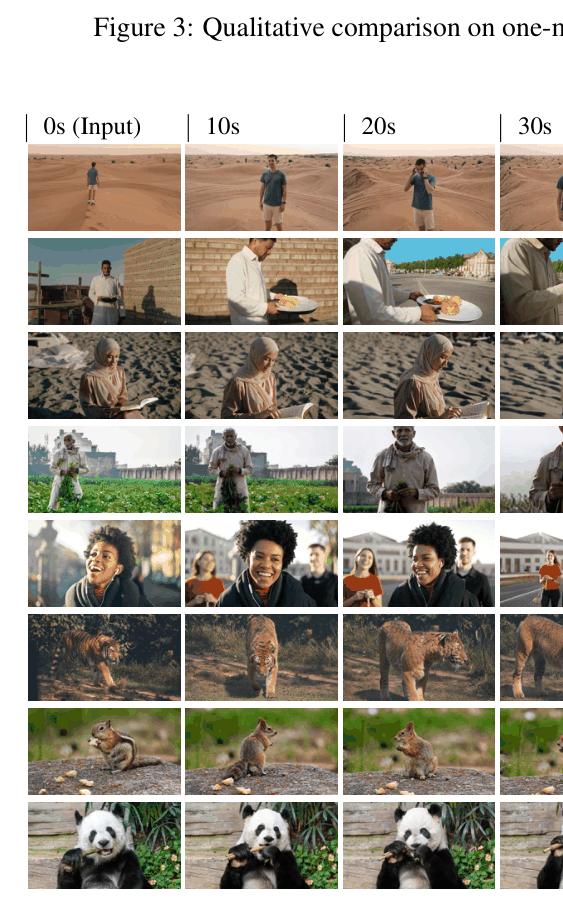
When generating a 60-second video, standard diffusion forcing models like SkyReel-V2 degrade into artifacts after ~20 seconds due to error accumulation. AAPT maintains coherence by training on its own generated past (student-forcing).
Key Novelty
Autoregressive Adversarial Post-Training (AAPT)
- Converts bidirectional attention to block-causal attention, enabling autoregressive generation of one latent frame (4 video frames) per forward pass
- Trains with a student-forcing adversarial objective where the generator inputs its own previous noisy predictions, mitigating error accumulation for long durations
- Uses a discriminator that evaluates multiple frame segments in parallel while the generator streams sequentially, combining efficient inference with robust training signals
Architecture
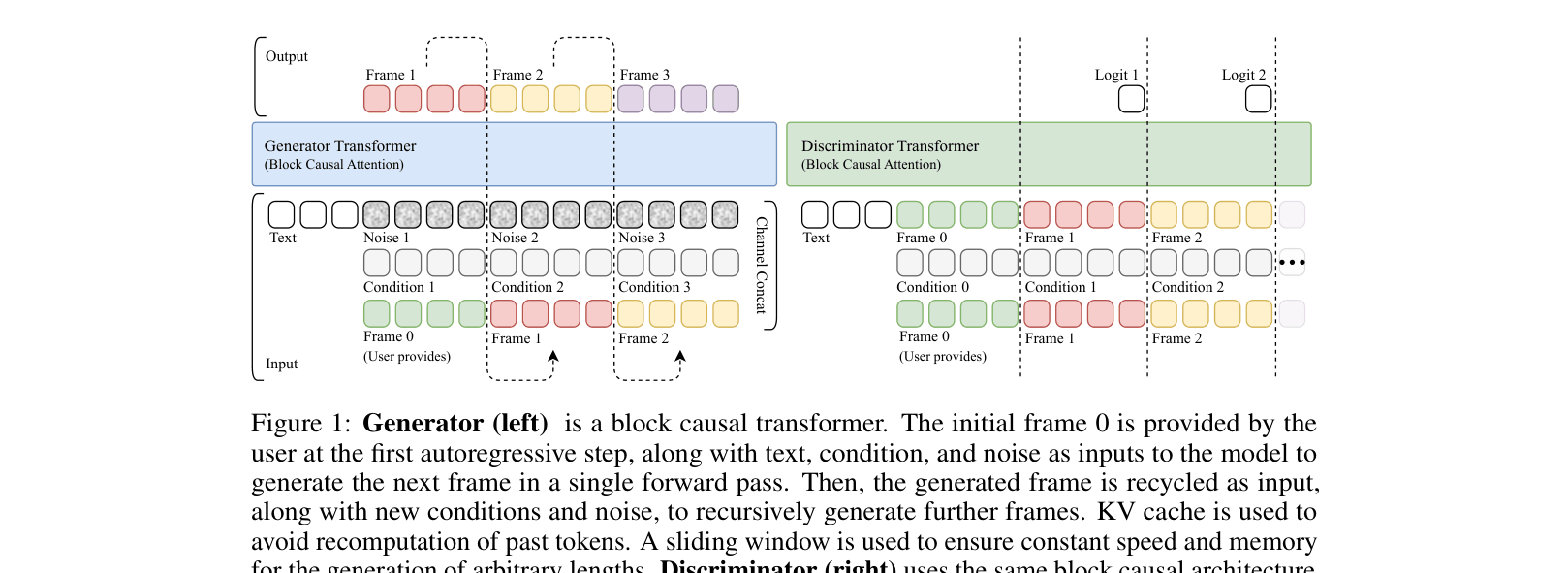
The Generator and Discriminator architectures. Generator uses block causal attention and recycles the generated frame as input for the next step. Discriminator parallels this but takes full segments.
Evaluation Highlights
- Achieves real-time 24fps generation at 736x416 resolution on a single H100 GPU (0.16s latency per step)
- Generates consistent 1-minute (1440-frame) videos, significantly outperforming SkyReel-V2 and MAGI-1 which degrade after ~20-30 seconds
- Outperforms state-of-the-art MotionCtrl and CameraCtrl2 on camera-conditioned world exploration metrics (FVD 61.33 vs 73.11)
Breakthrough Assessment
9/10
First method to achieve high-quality, real-time (24fps) infinite streaming video generation on a single H100 by successfully combining adversarial training with autoregressive diffusion distillation.