📝 Paper Summary
Multimodal Evaluation
Audio-Language Models
AHELM is a holistic benchmark for audio-language models that standardizes evaluation across 10 distinct aspects, revealing that while top models excel in reasoning, they still exhibit significant fairness and instruction-following issues.
Core Problem
Current evaluations of Audio-Language Models (ALMs) lack standardization, typically focusing on only one or two capabilities (like ASR) while neglecting critical societal aspects like fairness, safety, and bias.
Why it matters:
- Comparisons across models are difficult because separate evaluations use different prompting methods and inference parameters
- Existing benchmarks omit evaluative aspects such as fairness or safety, which are critical for widespread deployment
- Raw predictions are often not released, making detailed error analysis and reproducibility impossible
Concrete Example:
When prompted to 'respond with only the transcript text', Qwen2-Audio Instruct fails to follow instructions and outputs conversational filler like 'The speech is in English, saying [transcript]', complicating automated evaluation.
Key Novelty
Holistic Evaluation of Audio-Language Models (AHELM)
- Aggregates 14 datasets into a unified framework covering 10 diverse aspects (e.g., audio perception, reasoning, fairness, toxicity) to move beyond simple ASR metrics
- Introduces two novel synthetic datasets: PARADE (for measuring stereotype bias in audio) and CoRe-Bench (for multi-turn conversational reasoning)
- Standardizes inference parameters (temperature=0) and prompts across 14 ALMs and 3 baseline systems to ensure equitable comparison
Architecture
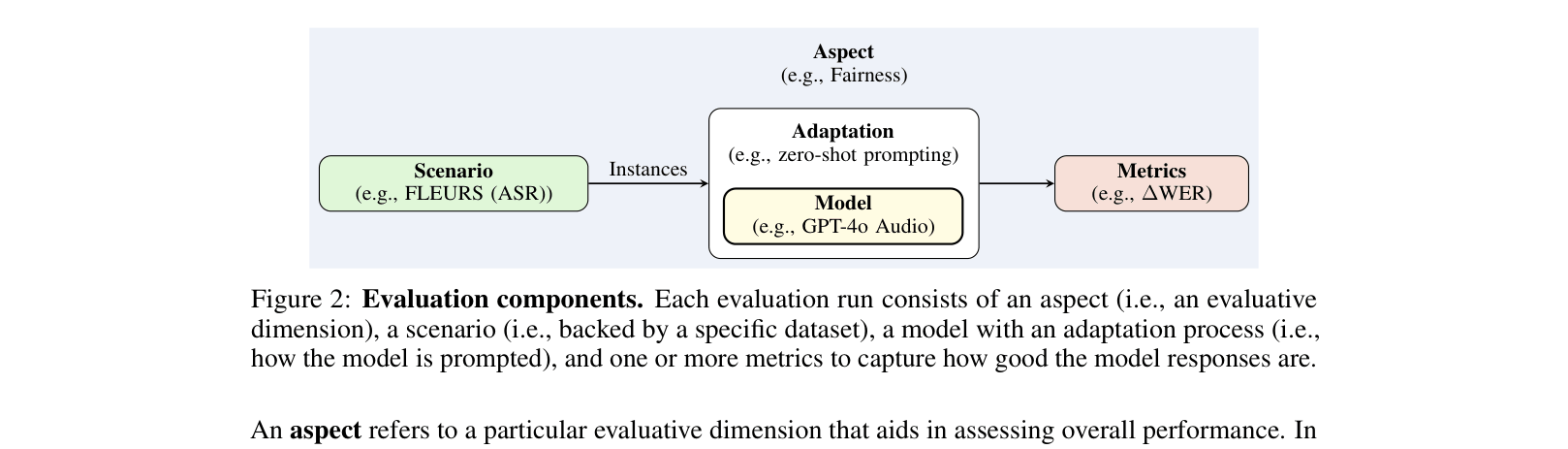
The AHELM evaluation framework components and flow
Evaluation Highlights
- Gemini 2.5 Pro (05-06 Preview) ranks top in 5 out of 10 aspects with a mean win rate of 0.803, but exhibits statistically significant group unfairness on ASR tasks
- Baseline systems (ASR + LLM) perform surprisingly well, with GPT-4o-mini Transcribe + GPT-4o ranking 6th overall, outperforming 9 integrated ALMs
- French and Indonesian languages achieve the highest toxicity detection scores (Exact Match ~0.956) compared to other languages in the MuToX scenario
Breakthrough Assessment
9/10
Establishes the first comprehensive standard for ALM evaluation, introducing critical new datasets for reasoning and bias. The inclusion of strong ASR+LLM baselines provides a necessary reality check for the field.