📊 Experiments & Results
Evaluation Setup
Generate 4 responses per prompt for 1000 test prompts; measure pairwise distance and predicted quality
Benchmarks:
- r/WritingPrompts (Open-ended creative story generation)
Metrics:
- reddit-reward (Predicted Upvote Score)
- Semantic Diversity (Mean Pairwise Cosine Distance of Jina Embeddings)
- Style Diversity (Mean Pairwise Cosine Distance of Style Embeddings)
- Statistical methodology: Not explicitly reported in the paper
Experiment Figures
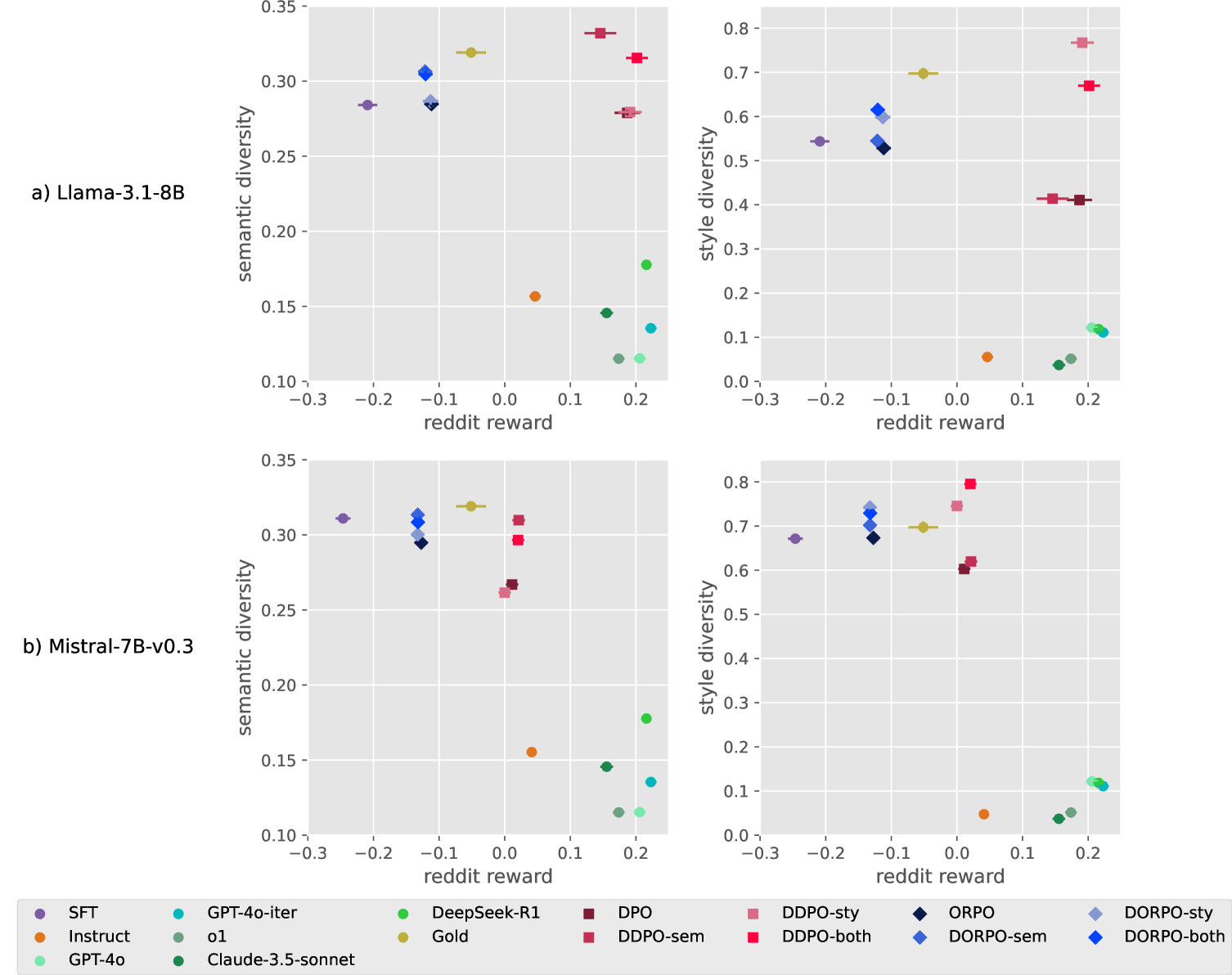
Scatter plot of Writing Quality (y-axis) vs. Diversity (x-axis) for various models
Main Takeaways
- Diversified DPO (DDPO) and ORPO (DORPO) successfully increase output diversity compared to their standard counterparts while maintaining similar quality levels.
- The 'DDPO-both' variant (mixing semantic and style deviation) achieves the best balance, reaching diversity levels comparable to human-written text.
- Existing instruction-tuned models (GPT-4o, Claude-3.5) cluster in a high-quality but low-diversity region, confirming the 'alignment tax' on creativity.
- The approach is robust across model architectures (Llama-3 vs Mistral-7B), though Llama-3-8B generally performed better.