📝 Paper Summary
Video Generation
Diffusion Model Acceleration
Adversarial Post-Training (APT) fine-tunes a pre-trained diffusion transformer directly on real data using a GAN-like objective to achieve one-step high-resolution video generation.
Core Problem
Generating high-resolution videos with diffusion models is prohibitively slow and expensive due to iterative denoising steps, while existing one-step distillation methods suffer significant quality degradation.
Why it matters:
- Generating just a few seconds of 1280x720 24fps video can take minutes on state-of-the-art GPUs (e.g., H100) using standard iterative diffusion.
- Existing video distillation methods are limited to low resolutions (512x512) and short durations (16 frames) or require multiple steps (4+ steps) for decent quality.
- Reducing inference to a single step enables real-time generation, drastically lowering computational costs and latency for end-users.
Concrete Example:
Standard diffusion models require 25+ steps to generate a video, often resulting in over-exposed or synthetic-looking footage due to Classifier-Free Guidance (CFG). APT generates a 2-second 720p video in a single step with better realism, though sometimes compromising structural integrity.
Key Novelty
Adversarial Post-Training (APT)
- Abandon the 'teacher-student' distillation paradigm where a model learns from a diffusion teacher's outputs; instead, directly train against real data using a GAN objective.
- Initialize the generator via consistency distillation but refine it using a massive discriminator (initialized from the diffusion model) that judges real vs. generated samples.
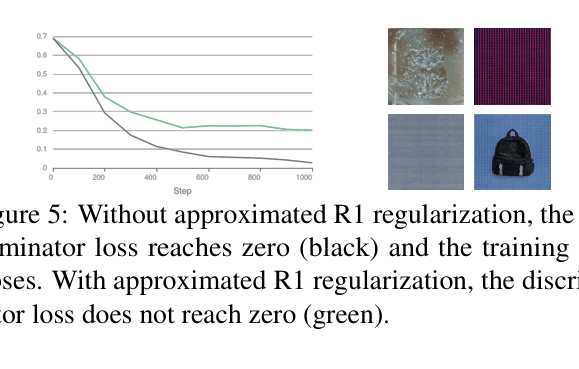
- Stabilize training of this huge GAN (~16B params) using an approximated R1 regularization that perturbs real data to penalize discriminator gradients without expensive double backpropagation.
Architecture
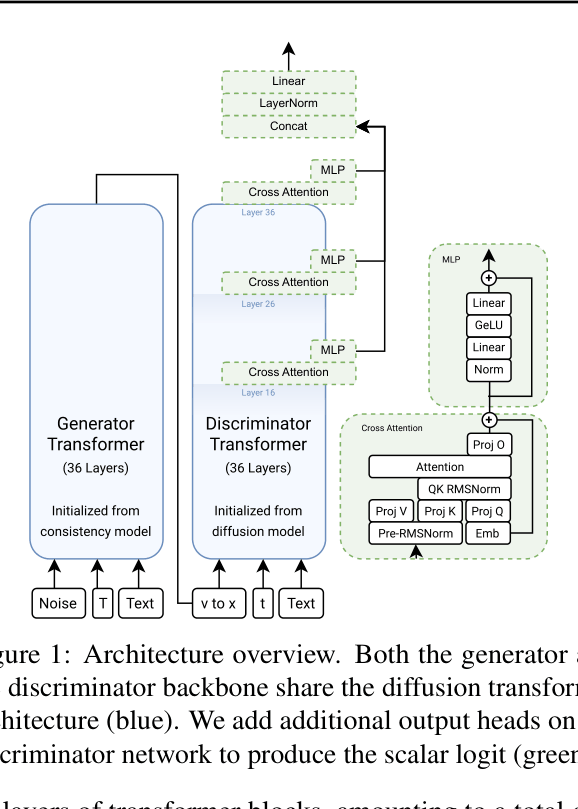
Overview of the Adversarial Post-Training architecture involving a Generator and Discriminator, both initialized from diffusion/consistency models.
Evaluation Highlights
- Achieves one-step generation of 1280x720 24fps videos (2 seconds) in real-time on an H100 GPU.
- Outperforms SD3.5-Large-Turbo in visual fidelity preference by +97.8% (relative adjusted score) in one-step image generation.
- Surpasses original 25-step diffusion baseline in visual fidelity (+32.3% preference) for video generation, despite some structural degradation.
Breakthrough Assessment
9/10
First demonstration of one-step 720p video generation at 24fps. Successfully trains one of the largest GANs ever (16B params), overcoming notorious stability issues.