📝 Paper Summary
Reward Modeling
Reinforcement Learning (RL)
Reasoning Evaluation
Libra introduces a reasoning-focused reward model benchmark and a generative reward model that uses Chain-of-Thought reasoning to verify answers, overcoming limitations of discriminative scoring.
Core Problem
Current reward models (RMs) struggle with complex reasoning tasks because they lack 'thinking' capabilities and rely on scalar scores that don't align with true correctness.
Why it matters:
- Predominant RL training relies on rule-based rewards requiring rigid formats and golden answers, hindering scaling with unlabeled data
- Existing RM benchmarks lack challenging questions and diverse responses from advanced reasoning models (like DeepSeek-R1), failing to accurately assess reasoning capabilities
- Standard discriminative RMs cannot effectively verify complex logic, acting as weak proxies for human judgment in hard reasoning scenarios
Concrete Example:
In complex math problems where the final answer is correct but the logic is flawed (or vice-versa), a standard discriminative RM might assign a high score based on surface features. Libra-RM uses a 'thinking' process to step-by-step verify the reasoning before outputting a judgment.
Key Novelty
Learning-to-Think for Generative Reward Models
- Treats the judging process as a verifiable reasoning task itself, where the Reward Model generates a Chain-of-Thought explanation before its final verdict
- Constructs a benchmark (Libra Bench) specifically designed to test RMs on hard math problems with responses from advanced reasoning models
- Optimizes the Reward Model using rejection sampling and reinforcement learning, mirroring the successful training recipes of reasoning LLMs
Architecture
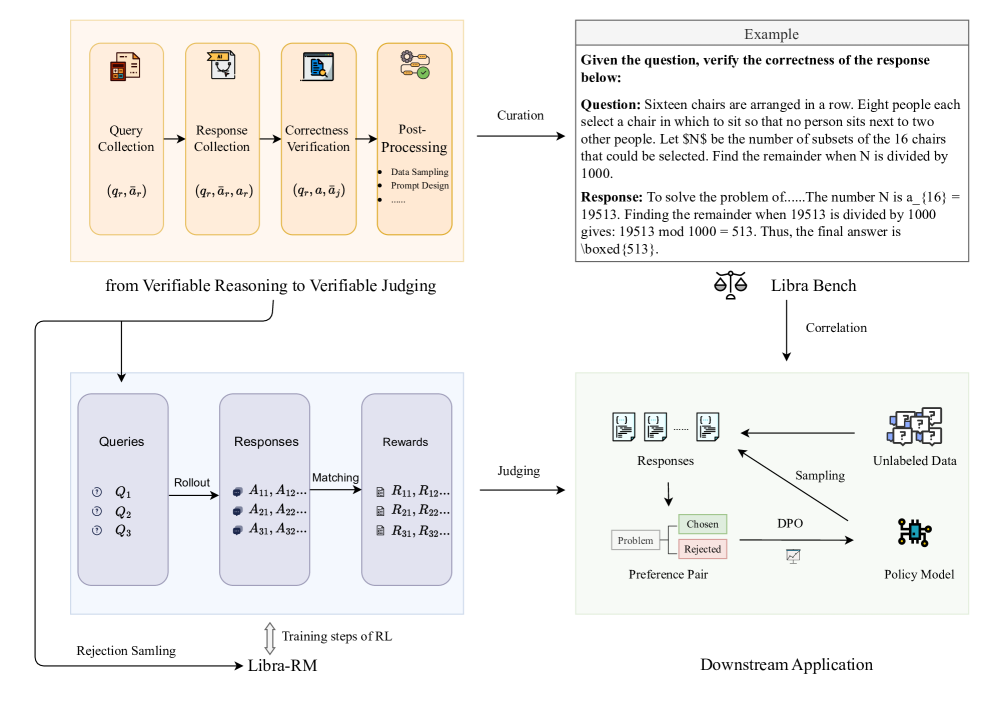
The overall framework for Libra Bench curation and Libra-RM training
Evaluation Highlights
- Libra-RM series achieves state-of-the-art results on reasoning-oriented benchmarks compared to existing RMs
- Reasoning models with 'thinking' capabilities (73.7%-78.7% accuracy) significantly outperform non-thinking models (55.1%-69.1%) on Libra Bench
- Demonstrates strong correlation between performance on Libra Bench and downstream RL application performance
Breakthrough Assessment
8/10
Strong contribution by applying 'thinking' (inference-time scaling) to the Reward Model itself, rather than just the policy model. The curated benchmark addresses a critical gap in evaluating reasoning RMs.