📝 Paper Summary
Reinforcement Learning for Reasoning
Sparse Reward Optimization
Process Mining for LLMs
TACReward improves mathematical reasoning in large language models by using process mining to align the structural reasoning steps of a student model with a teacher model, generating a scalar proxy reward.
Core Problem
Sparse reward methods (like GRPO) rely on binary outcome correctness, which fails to distinguish between good and bad reasoning steps within incorrect answers, leading to weak learning signals.
Why it matters:
- Binary outcome rewards produce uniform signals for grouped responses, failing to differentiate near-correct reasoning from complete hallucinations
- Process Reward Models (PRMs) require expensive human annotation for step-level labels and are difficult to integrate into sparse reward frameworks without architectural changes
- Existing proxy rewards often estimate overall quality indirectly rather than evaluating the logical integrity of individual reasoning steps
Concrete Example:
When a student model solves a math problem, it might use 8 correct reasoning steps but fail at the final calculation, receiving a 0 reward (same as a completely nonsensical answer). TACReward assigns a partial score (e.g., 0.8) by detecting that the reasoning structure aligns well with a teacher's trace.
Key Novelty
Trace, Alignment, and Check Reward (TACReward)
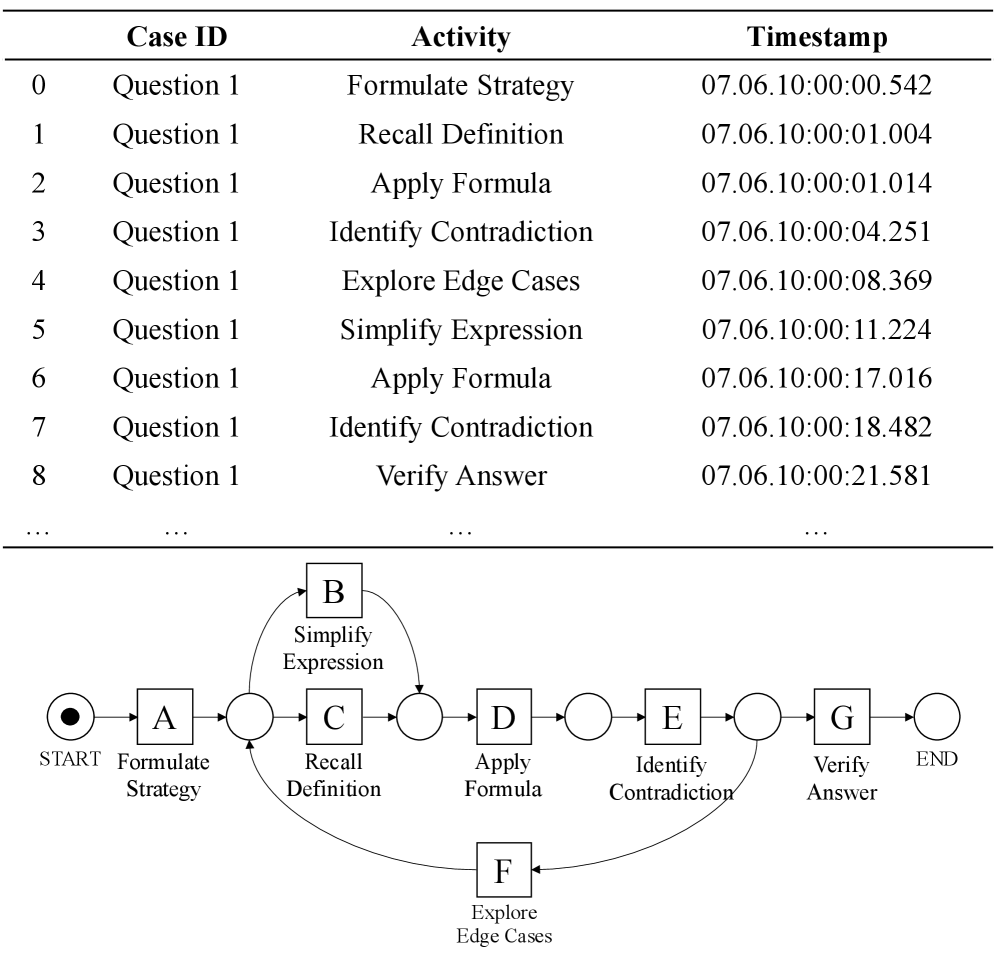
- Treats reasoning chains as structured processes (traces) of distinct activities (e.g., 'Define Variable', 'Calculate') rather than just text
- Uses process mining alignment techniques to map student reasoning steps to a teacher's reference trace, calculating costs for missing or redundant steps
- Computes a scalar conformance score based on 'fitness' (completeness) and 'precision' (avoiding hallucinated steps) to serve as a proxy reward in sparse RL settings
Architecture
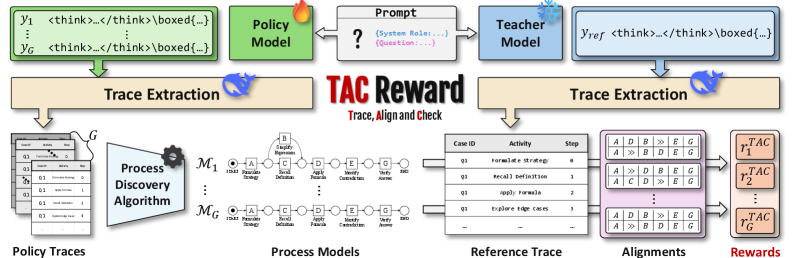
Overview of the TACReward pipeline: (1) Trace extraction from Policy and Teacher, (2) Process Discovery from Policy Trace, (3) Alignment with Teacher Trace, (4) Conformance Checking to produce scalar reward.
Evaluation Highlights
- +89.2% relative improvement in average accuracy for GSPO + TACReward compared to GSPO alone across five mathematical benchmarks (excluding contaminated ones)
- Consistent performance gains over RLOO (+6.1%) and GRPO (+12.7%) baselines on the Qwen2.5-7B-Instruct model
- Achieves 32.5% average accuracy with GSPO+TAC vs 17.2% with GSPO alone on challenging math tasks like MINERVA and OlympiadBench
Breakthrough Assessment
7/10
Novel application of process mining to LLM reasoning. Provides a clever way to get 'dense-like' signal from sparse rewards without human labels, showing significant gains on top of recent methods like GRPO/GSPO.