📝 Paper Summary
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
Interpretability in LLMs
SRM enhances reward modeling by running lightweight 'side-branch' models to generate explicit features (like factuality and style) which are then concatenated with the input to guide the final reward score.
Core Problem
Traditional scalar Reward Models (RMs) output a single score without accessing external context or reasoning, leading to incomplete evaluations, while Generative RMs (GRMs) are slow, uninterpretable black boxes.
Why it matters:
- Industrial systems (search/recommendation) require structured feedback to diagnose why a response is bad (e.g., wrong facts vs. poor style), which scalar RMs cannot provide
- GRMs rely on sequential decoding, making them too inefficient for high-throughput real-world deployment
- Without explicit feature extraction, RMs often hallucinate preferences based on surface-level text patterns rather than factual correctness
Concrete Example:
In a case study about coffee benefits, a baseline RM incorrectly favors a rejected response (score 0.68 vs 0.52) due to surface features. The SRM identifies specific entity details (cardiovascular benefits) via its side-branches, correctly scoring the chosen response higher (0.91 vs 0.32).
Key Novelty
Structural Reward Model (SRM) with Side-Branch Models (SBMs)
- Decomposes the evaluation process into modular 'side-branches' that independently generate auxiliary text features (e.g., checking facts, analyzing style)
- Concatenates these explicit auxiliary texts with the original prompt-response pair before feeding them into the final scalar reward model
- Uses 'LLM-as-a-judge' (o1 model) to filter training data for these side-branches, ensuring high-quality feature generation
Architecture
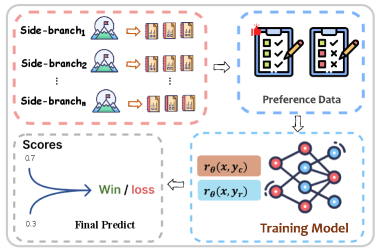
Overview of the Structural Reward Model framework showing parallel side-branch models feeding into a central reward model.
Evaluation Highlights
- +49.5% improvement in overall score for Llama3-8B-Instruct (11.3% -> 60.8%) after integrating SRM modules
- +66.1% improvement on RM-Bench Normal setting for Llama3-8B-Instruct (9.3% -> 75.4%)
- +56.8% improvement on JudgeBench Knowledge subset for Llama3-8B-Instruct (2.6% -> 59.4%)
Breakthrough Assessment
7/10
Significant performance jumps reported over scalar baselines. The modular architecture addresses the key bottleneck of interpretability in reward modeling, though it relies on distillation from stronger models (o1).