📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
LLM Alignment
Using an ensemble of reward models with conservative optimization objectives (like worst-case or uncertainty-weighted scoring) prevents RLHF policies from exploiting flaws in proxy reward models.
Core Problem
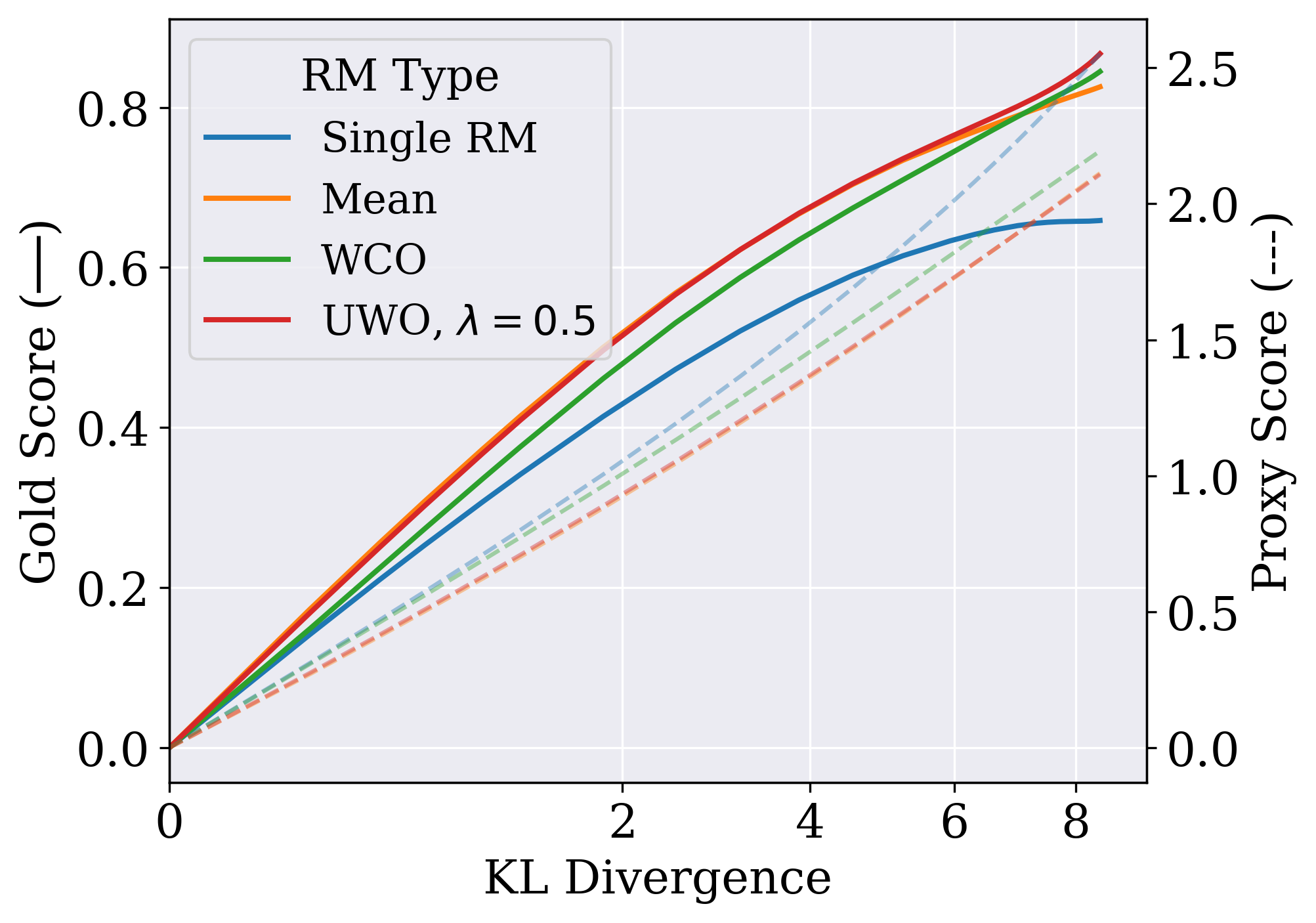
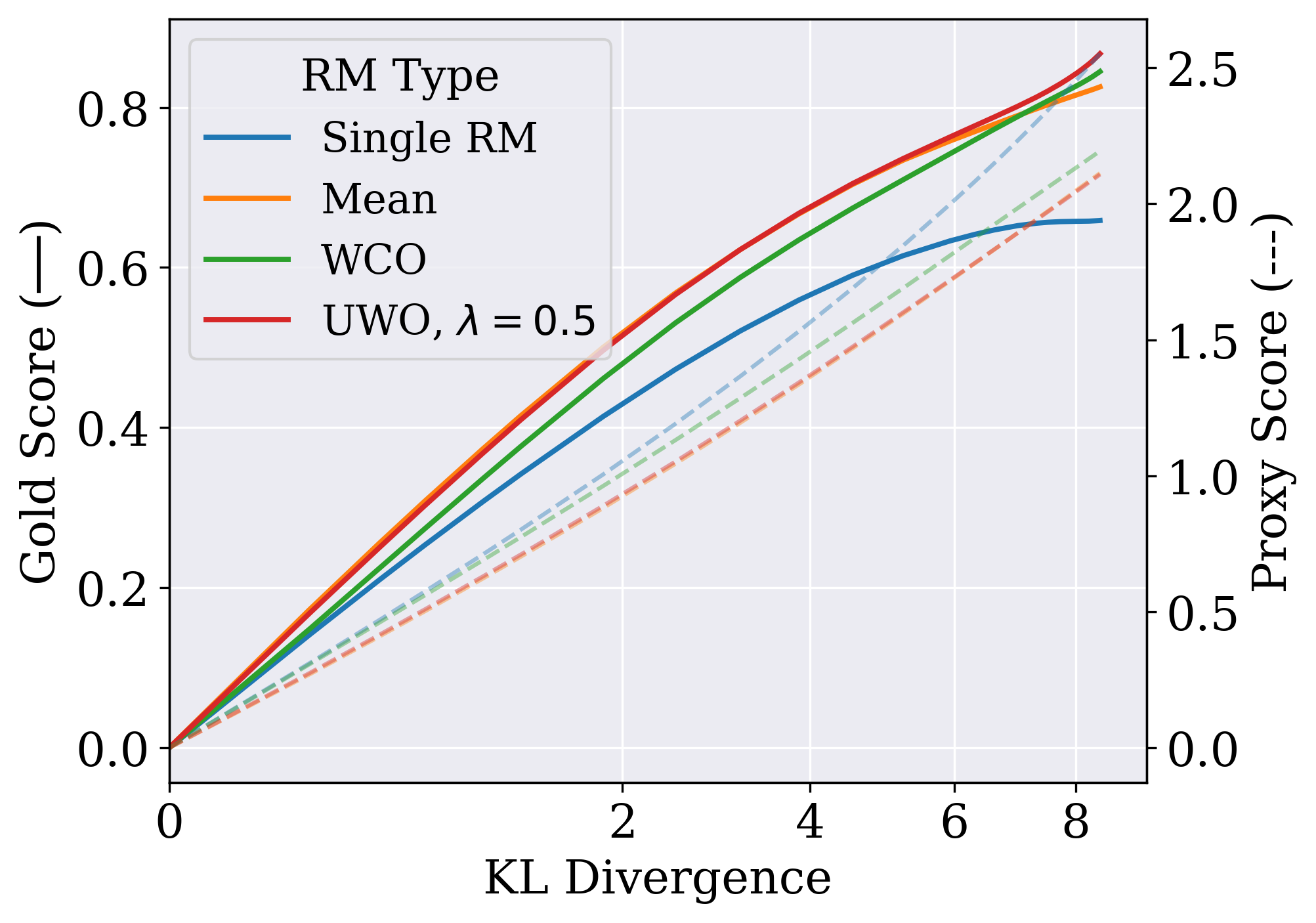
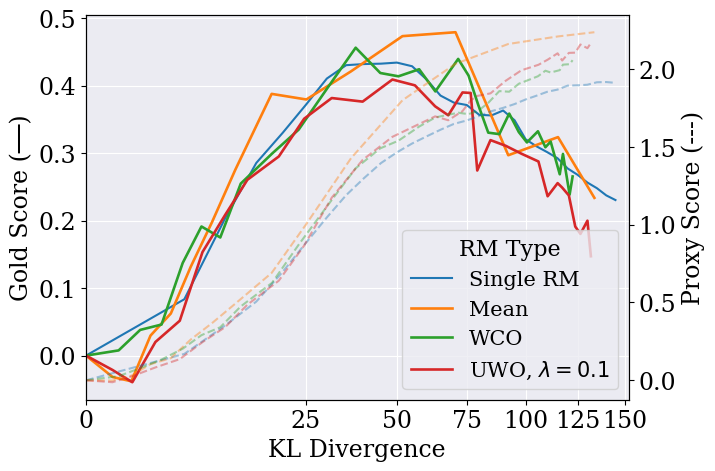
In RLHF, policies are optimized against an imperfect proxy reward model; eventually, the policy learns to exploit errors in this proxy, increasing the proxy score while degrading true performance (overoptimization).
Why it matters:
- Overoptimization causes language models to produce gibberish or harmful outputs that technically score high on the reward model but fail the user's intent.
- Scaling up reward models to fix this is computationally expensive and requires significant pretraining, which isn't always feasible.
- Existing methods rely on single reward models, which are fragile to label noise and inherent approximation errors.
Concrete Example:
A policy might generate a nonsensical answer that happens to contain specific keywords the reward model overvalues. Optimizing against a single reward model would encourage this gibberish, whereas an ensemble would likely disagree on its quality, flagging it as uncertain.
Key Novelty
Ensemble-Based Conservative Optimization for RLHF
- Instead of training one reward model, train multiple copies (ensemble) using different seeds to capture uncertainty.
- During policy optimization, score responses using conservative aggregation: take the lowest score (Worst-Case) or penalize high variance (Uncertainty-Weighted) to discourage the policy from visiting areas where reward models disagree.
Architecture
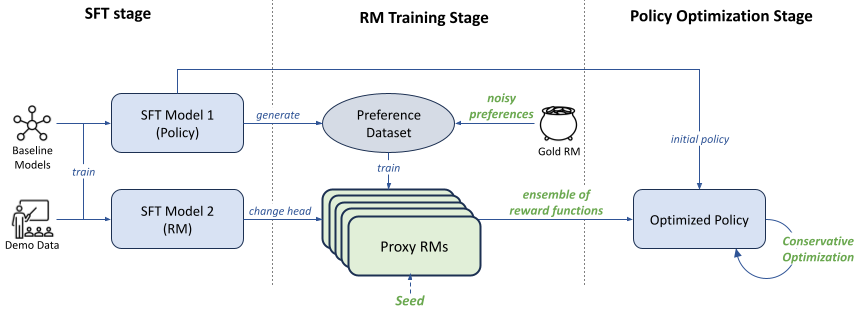
The modified RLHF pipeline comparing standard approaches vs. the proposed ensemble approach.
Evaluation Highlights
- Eliminates overoptimization for Best-of-N sampling, improving performance by up to ~75% in settings with 25% label noise.
- Outperforms single reward model optimization in PPO, and when combined with a small KL penalty (0.01), successfully eliminates overoptimization without performance cost.
- Gains are orthogonal to model scaling: ensembles improve performance even when added to larger reward models (up to 1.3B parameters).
Breakthrough Assessment
7/10
Provides a practical, effective solution to a major RLHF failure mode (overoptimization) using well-understood ensemble techniques. While conceptually simple, the systematic empirical validation makes it a strong contribution.