📝 Paper Summary
Reward Modeling
AI Alignment
Reasoning Evaluation
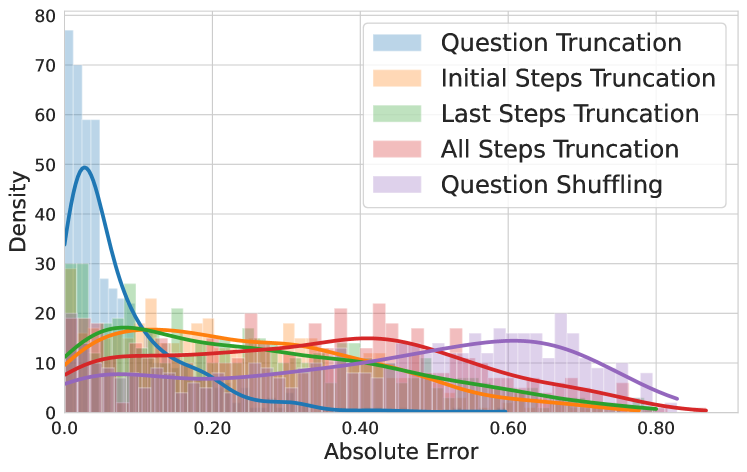
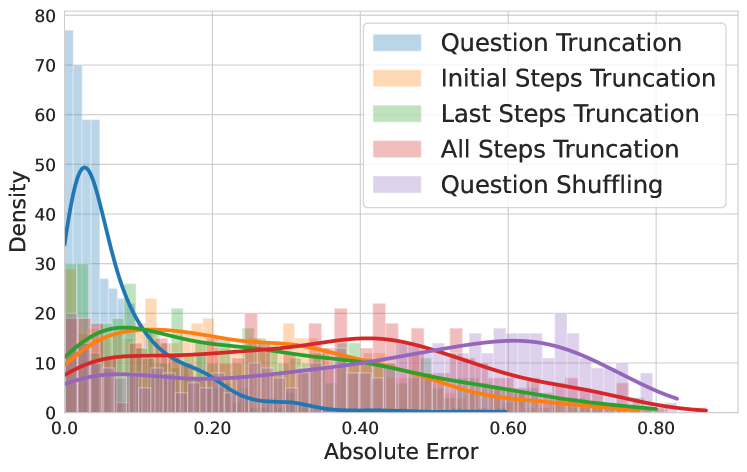
State-of-the-art reward models evaluate the structural coherence and length of reasoning chains rather than valid causal links, evidenced by their inability to distinguish between complete problems and those with the question removed.
Core Problem
Reward models (RMs) are assumed to verify the logical correctness of reasoning, but their internal decision-making mechanisms are opaque; it is unclear if they truly understand the problem or just rely on learned surface patterns.
Why it matters:
- RMs are critical for scaling test-time computation and aligning LLMs (RLHF), so their failure to verify causality could lead to 'reward hacking' where models generate coherent but incorrect nonsense
- If RMs ignore the problem statement, they cannot reliably evaluate novel or complex reasoning tasks where the question details are crucial for the answer
Concrete Example:
When the problem statement is completely deleted from the input (leaving only the solution steps), the reward model's score changes very little, indicating it was never actually checking if the solution answered that specific question.
Key Novelty
Consistency-over-Causality Hypothesis
- Demonstrates that RMs prioritize 'structural consistency' (does the solution look like a good solution?) over 'causal correctness' (does this solution answer this question?)
- Uses systematic input truncation (removing questions, removing steps) to prove RMs rely heavily on the presence of complete reasoning trajectories rather than problem comprehension
Architecture

Systematic error analysis framework showing how different input truncations (removing question, shuffling, modifying numbers) are fed into the Reward Model to measure deviation from the original score.
Evaluation Highlights
- Question truncation (removing the prompt entirely) results in the lowest absolute error in reward scores, implying the question is largely ignored
- All-steps truncation (leaving only the final answer) produces the highest errors, showing RMs depend on the 'shape' of reasoning steps to assign value
- Modifying numerical values in the question causes significant reward error, indicating RMs check local consistency (do numbers match?) rather than global logic
Breakthrough Assessment
8/10
Provides a crucial negative result about the current state of Reward Modeling, challenging the assumption that RMs act as logical verifiers. The finding that 'questions matter little' is counter-intuitive and significant for the field.