📝 Paper Summary
Controllable Text Generation
Safety Alignment
RAD steers language model generation by reweighting next-token probabilities using a small, unidirectional reward model that caches activations to minimize computational overhead.
Core Problem
Controlling LLMs via retraining is prohibitively expensive, while existing decoding-time methods are computationally inefficient ($O(km^2)$) or degrade generation quality.
Why it matters:
- LLMs frequently generate toxic or biased content when deployed in the wild, posing safety risks
- Retraining or fine-tuning (RLHF) large models like LLaMA-65B requires massive compute resources unavailable to many researchers
- Previous weighted decoding methods require re-encoding the entire sequence for every candidate token, causing high latency
Concrete Example:
When a user provides a prompt like 'The abrupt end to...', a standard LLM might complete it with toxic text. Existing methods like GeDi must re-process the full sentence for every potential next word to check for toxicity, slowing generation to a crawl.
Key Novelty
Unidirectional Reward-Augmented Decoding (RAD)
- Uses a decoder-only Transformer as a reward model, allowing it to process text left-to-right and cache past activations (similar to the base LLM)
- Scores the top-k candidate tokens at each step based on how well they align with a target attribute (e.g., non-toxicity)
- Rescales the base LLM's token probabilities using these reward scores to steer generation without retraining the base model
Architecture
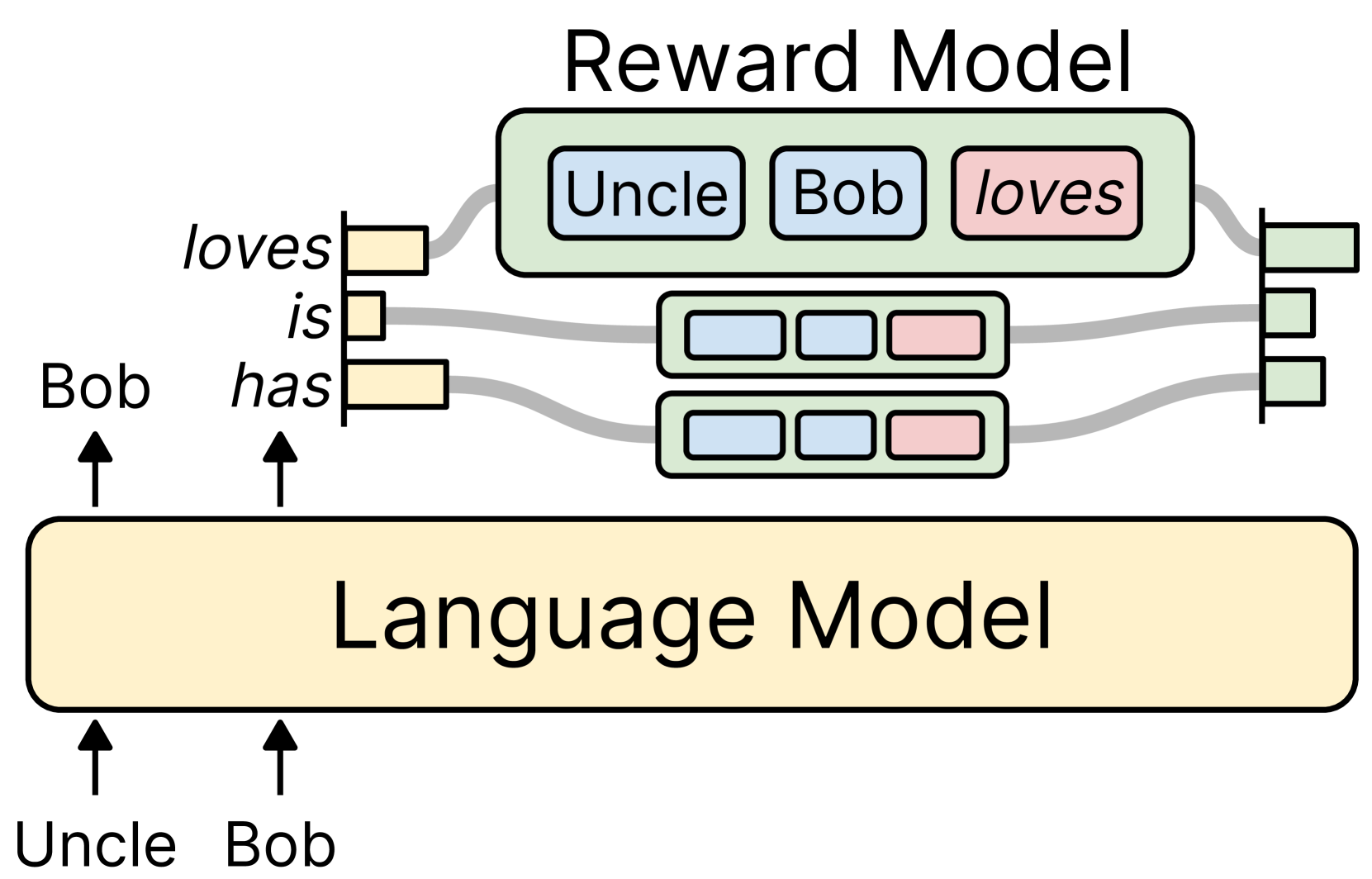
Overview of the Reward-Augmented Decoding process
Evaluation Highlights
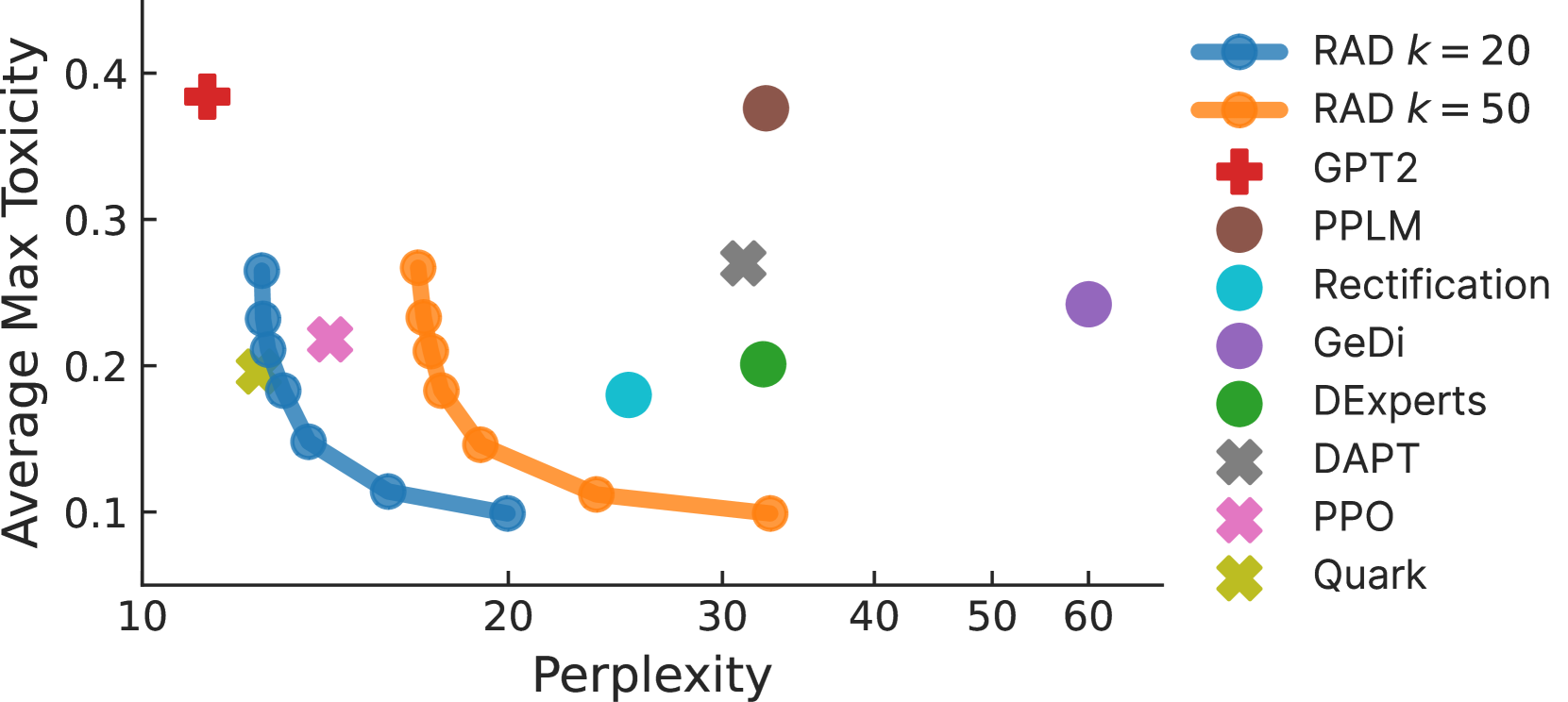
- Achieves comparable detoxification performance to PPO and Quark (methods requiring training) while only modifying the decoding process
- Incurs only ~3% computational overhead when applied to LLaMA-65B with a GPT-2 Small reward model
- Reduces time complexity of scoring k candidates from quadratic $O(km^2)$ to linear $O(km)$ via activation caching
Breakthrough Assessment
7/10
Significant efficiency improvement for inference-time control, making weighted decoding practical for very large models. However, relies on existing model architectures and standard sampling strategies.