📝 Paper Summary
Mechanistic Interpretability
Reward Modeling
LLMs contain a sparse, intrinsic reward subsystem where a small set of 'value neurons' predicts correctness and 'dopamine neurons' encode reward prediction errors, mirroring biological brain mechanisms.
Core Problem
While LLM hidden states are known to encode information about confidence and correctness, the specific intrinsic mechanisms and neuronal structures responsible for these representations remain largely unidentified.
Why it matters:
- Most existing work uses hidden states for auxiliary tasks (hallucination detection) without explaining *why* the representations possess these capabilities
- Understanding the internal 'brain-like' structures of LLMs allows for more targeted interventions to improve reasoning reliability
- Identifying specific neurons responsible for value estimation proves that reward processing is a sparse, modular phenomenon rather than a diffuse property
Concrete Example:
When a model generates a math solution, it may internally 'know' the steps are correct or incorrect before finishing. Current black-box approaches can't pinpoint which specific neurons hold this expectation. This paper identifies specific neurons that, if switched off, cause the model to lose this internal guidance and fail the task.
Key Novelty
Biological Reward Subsystem Analogy in LLMs
- Identifies 'Value Neurons' (analogous to vmPFC/OFC in brains) that sparsely encode the expected value of the current state
- Identifies 'Dopamine Neurons' (analogous to VTA/SNc in brains) that encode Reward Prediction Error (RPE)—activating when rewards exceed expectations and deactivating when they fall short
- Demonstrates that this subsystem is extremely sparse (<1% of neurons) yet essential for reasoning performance
Architecture
Conceptual flow: Hidden States -> Sparse Value Probe -> Reward Prediction
Evaluation Highlights
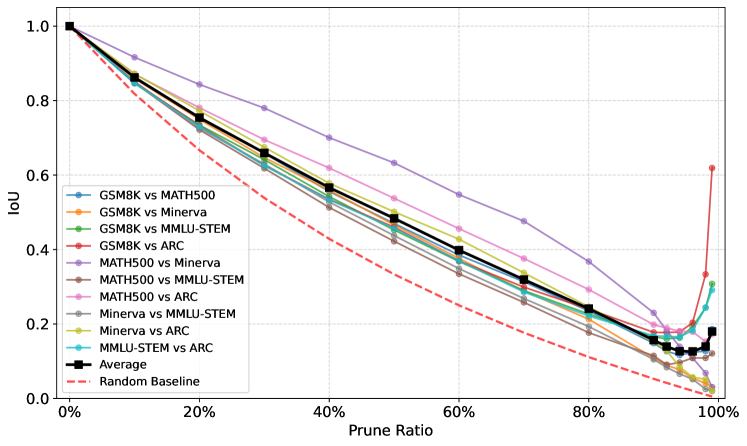
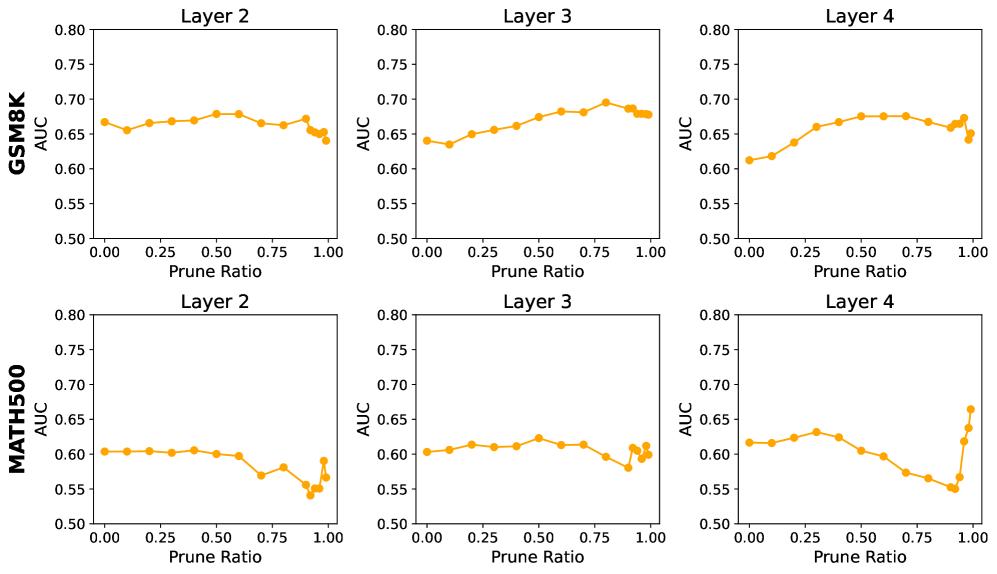
- Value neurons are highly sparse: Probe AUC (Area Under Curve) remains stable even when pruning >99% of input neurons
- Critical for reasoning: Zeroing out just 1% of identified value neurons causes 'significant' performance degradation on MATH500, whereas random ablation has no effect
- High transferability: The Intersection over Union (IoU) of value neurons between GSM8K and ARC datasets exceeds 0.6 even at a 99% pruning ratio
Breakthrough Assessment
8/10
Strong mechanistic finding linking LLM internals to biological reinforcement learning structures. The demonstration of sparsity and cross-model/dataset robustness suggests a fundamental property of transformer-based reasoning.