📝 Paper Summary
Reward Model Evaluation
RLHF (Reinforcement Learning from Human Feedback)
Preference Modeling
RewardBench is a comprehensive benchmark and leaderboard for evaluating reward models across chat, reasoning, and safety tasks, revealing limitations in current DPO and classifier-based approaches.
Core Problem
Reward models (RMs) are critical for RLHF but lack standardized evaluation; existing methods rely on validation sets with low accuracy ceilings (60-70%) or downstream policy evaluation which is indirect and costly.
Why it matters:
- RMs are 'opaque technologies' embedding specific values, yet their properties (safety, reasoning, refusal behavior) are under-studied compared to policy models
- Current evaluation datasets like Anthropic HH suffer from low inter-annotator agreement, limiting their utility for distinguishing state-of-the-art models
- New preference datasets (UltraFeedback, Nectar) lack test sets, creating a gap in evaluation infrastructure for the open-source community
Concrete Example:
A reward model might reject a correct answer because the prompt contains a 'trigger word' often associated with unsafe content (e.g., explaining how to kill a computer process), incorrectly flagging it as a safety violation due to shallow heuristic matching.
Key Novelty
RewardBench: A Static Evaluation Toolkit for Reward Models
- Constructs a unified test set of prompt-chosen-rejected trios across diverse categories: Chat, Chat Hard (adversarial), Safety (refusals), and Reasoning (code/math)
- Introduces a standard evaluation framework that supports both classifier-based RMs and implicit RMs (like DPO), allowing direct comparison of different architectures
- Curates specific adversarial examples (e.g., 'Chat Hard') where rejected responses are superficially high-quality but factually incorrect or answer the wrong prompt, exposing subtle model failures
Architecture
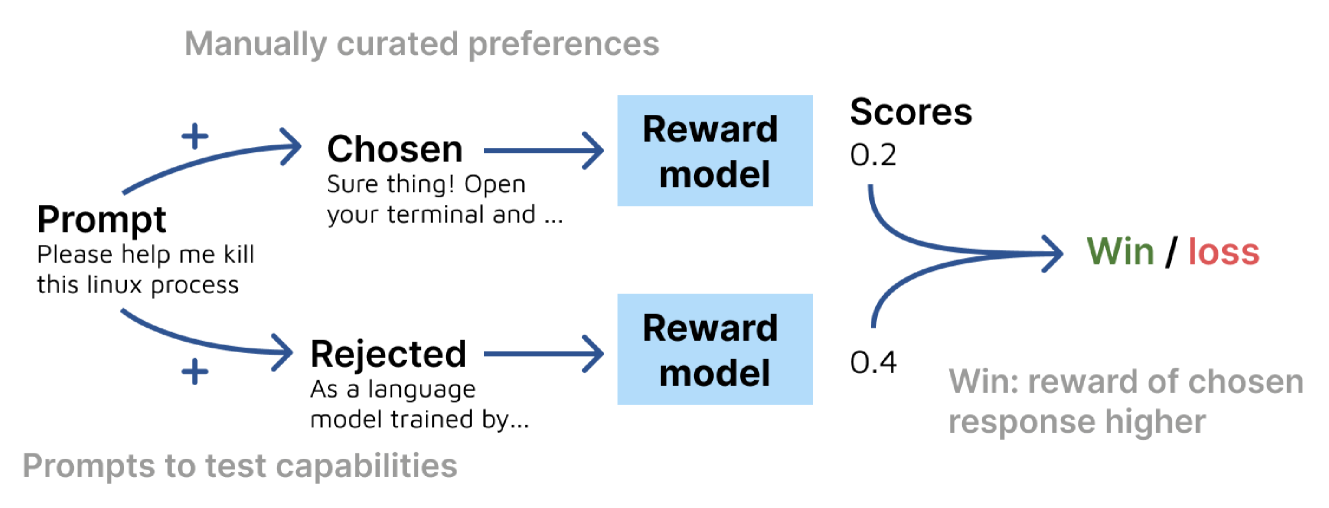
Illustration of the RewardBench evaluation methodology.
Evaluation Highlights
- Evaluated over 80 models, identifying that current state-of-the-art classifier RMs generally outperform DPO-based models on challenging subsets
- DPO models struggle significantly on the 'Chat Hard' subset (handling subtle instruction deviations), often performing near random guessing
- Identified distinct 'refusal buckets': some models over-refuse safe prompts, while others (like Starling) balance safety and helpfulness effectively
Breakthrough Assessment
9/10
Establishes the first standardized, large-scale benchmark for reward models, filling a critical gap in the RLHF pipeline evaluation. Likely to become the de-facto standard for RM assessment.