📊 Experiments & Results
Evaluation Setup
Cross-evaluation of models on benchmarks designed for the 'opposing' field
Benchmarks:
- RewardBench-M (Translation Preference (identifying better translation))
- SEAHORSE (Summarization Attribution/Factuality)
Metrics:
- Citation Overlap Percentage
- Accuracy (Preference prediction)
- Pearson Correlation (Attribution scoring)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Bibliometric analysis quantifies the extreme separation between the two research communities. | ||||
| Semantic Scholar Graph (2021-2025) | Inter-field citation % | 40.0 | 10.0 | -30.0 |
| Inter-rater agreement analysis shows high model-model agreement despite lower accuracy against ground truth. | ||||
| SEAHORSE | Agreement Rate | 73.0 | 89.0 | +16.0 |
Experiment Figures
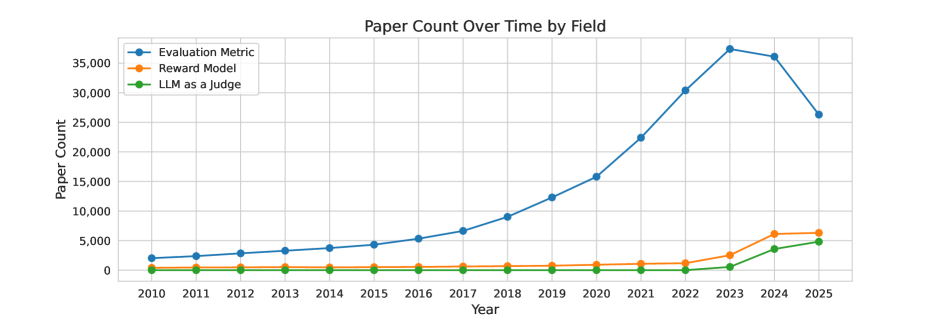
The number of papers per year containing specific strings ('Evaluation Metric', 'Reward Model', 'LLM-as-a-judge') from 2021 to 2025.
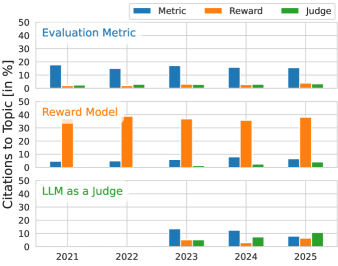
Citation graph analysis showing the percentage of citations that flow within a field vs. between fields.
Distribution of publication venues for cited papers (e.g., ML venues vs NLP venues).
Main Takeaways
- Bibliometric analysis confirms the fields are siloed: <10% of citations cross between Reward Modeling and Evaluation Metrics.
- Metrics can be SOTA Reward Models: CometKiwi (a metric) matches or outperforms specialized Reward Models on the RewardBench-M translation task.
- Reward Model techniques (LLM-as-a-judge) struggle as Metrics: On SEAHORSE (factuality), dedicated metrics outperform even advanced LLMs like GPT-5 and Gemini 2.5 Pro.
- The fields use different terms for identical concepts (e.g., 'segment-level meta-evaluation' is equivalent to 'preference optimization signal'), impeding knowledge transfer.