📝 Paper Summary
Process Reward Models (PRM)
Reinforcement Learning for Reasoning
Synthetic Data Generation
ER-PRM derives a theoretically grounded process reward formulation from KL-regularized RL, labeling reasoning steps based on their potential to reach the correct answer relative to a reference policy.
Core Problem
Existing automatic process reward labeling methods (like Math-Shepherd) use traditional MDP frameworks that ignore the KL-regularization constraint standard in modern LLM alignment, leading to suboptimal reward signals.
Why it matters:
- Mathematical reasoning requires accurate step-by-step verification, but human annotation is prohibitively expensive
- Current automatic labeling methods lack theoretical alignment with the entropy-regularized objective used in RLHF, potentially causing the policy to deviate too far from the base model
- High-quality process rewards are the upper bound for reasoning performance in inference-time search and training-time alignment
Concrete Example:
In Math-Shepherd, a step's score is simply the raw probability of reaching a correct answer. However, this ignores the prior probability of the step under the reference model. A step might have high success probability simply because it's a common path, not because it's inherently 'better' relative to the reference, leading to miscalibrated rewards.
Key Novelty
Entropy-Regularized Process Reward Model (ER-PRM)
- Formulates the reward modeling problem under an entropy-regularized MDP framework, aligning the reward definition with the standard KL-constrained RL objective
- Derives a specific 'soft-max' style reward calculation where the value of a step is determined by the aggregated exponential rewards of possible completions sampled from the reference policy
- Uses this derived formula to automatically label reasoning steps generated by Monte Carlo sampling, creating a dataset for training a dense reward model
Architecture
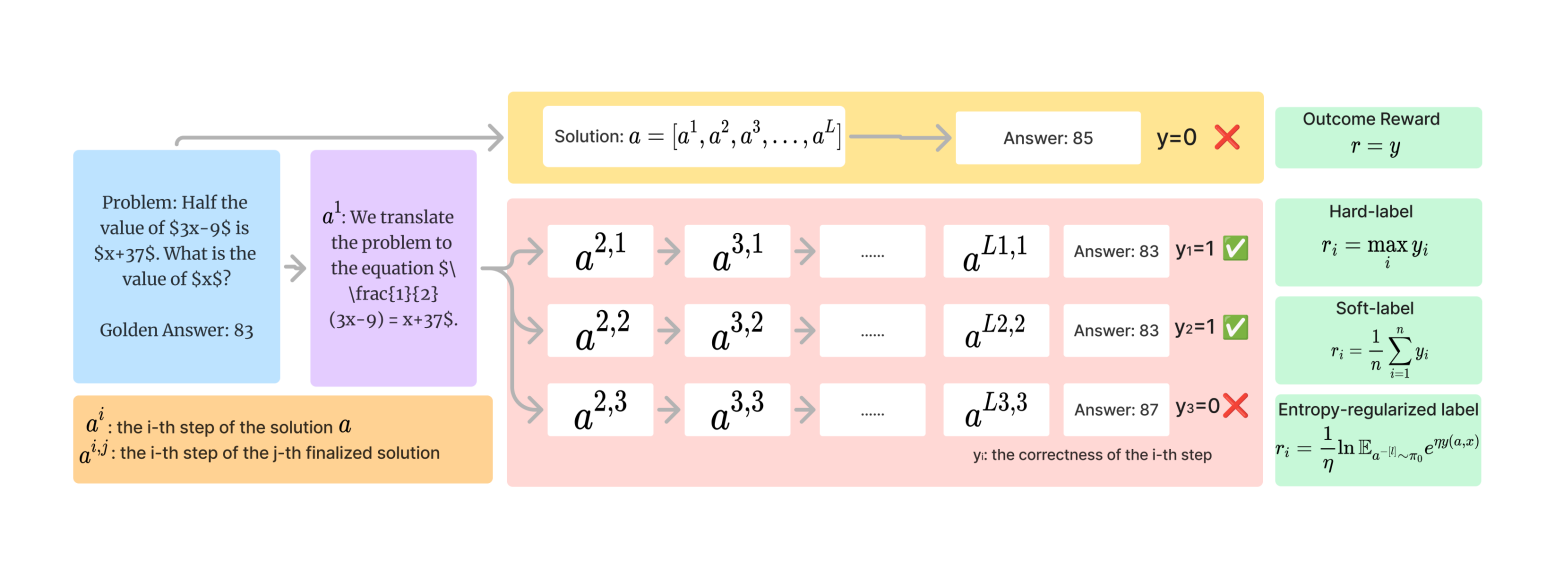
Comparison of reward calculation methods: Hard-label PRM vs. Soft-label PRM (Math-Shepherd) vs. ER-PRM (Ours).
Evaluation Highlights
- +2-3% improvement on MATH benchmark using Best-of-N sampling compared to existing process reward models
- Achieves 1% improvement on GSM8K benchmark over baselines
- Substantial performance gains in RLHF (rejection sampling fine-tuning), outperforming policy models trained with Hard-label PRM, Soft-label PRM, and Outcome Reward Models
Breakthrough Assessment
7/10
Provides a strong theoretical grounding for process reward construction that was previously heuristic. Empirical gains are consistent and significant, though the core mechanism is a refinement of Math-Shepherd rather than a completely new paradigm.