📝 Paper Summary
Visual Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
JRM aligns discriminative reward models with generative reasoning capabilities by jointly optimizing preference ranking and language modeling on a shared backbone, enabling efficient inference without explicit text generation.
Core Problem
Existing reward models face a trade-off: discriminative models are efficient but struggle with complex semantics, while generative models have strong reasoning but are computationally expensive and difficult to align with human preferences.
Why it matters:
- Image editing tasks require verifying global semantic consistency and logical constraints, which shallow discriminative models often miss
- Generative reward models (using explicit Chain-of-Thought) introduce high latency, making them impractical for large-scale online reinforcement learning loops
- The mismatch between language modeling objectives and preference ranking makes it hard to align generative models directly with human comparison data
Concrete Example:
In an image editing task, a discriminative model might rely on surface-level similarity and fail to penalize a result that ignores a 'change material to wood' instruction. A generative model could explain the error but is too slow to use repeatedly during RL training. JRM internalizes this reasoning into the score.
Key Novelty
Latent Chain-of-Thought (Latent CoT)
- Jointly trains a shared vision-language backbone on two objectives: preference ranking (discriminative) and explanation generation (generative)
- Language supervision forces the shared representation to encode deep semantic structure and reasoning logic
- At inference time, the language head is discarded, retaining the 'internalized' reasoning capabilities in the efficient discriminative scoring head
Architecture
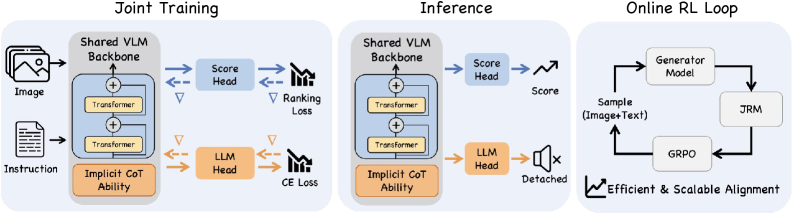
The JRM framework illustrating the shared backbone and dual-head training strategy.
Evaluation Highlights
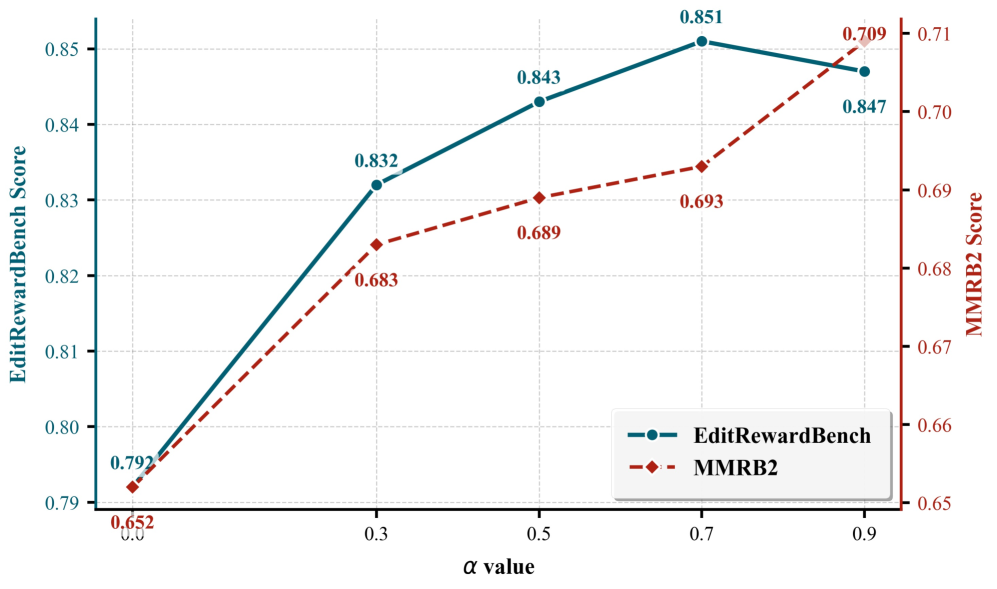
- Achieves 85.1% accuracy on EditReward-Bench, outperforming GPT-5 (75.5%) by 9.6%
- Reaches 69.3% composite score on MMRB2 benchmark, surpassing GPT-5 (61.9%) by 7.4%
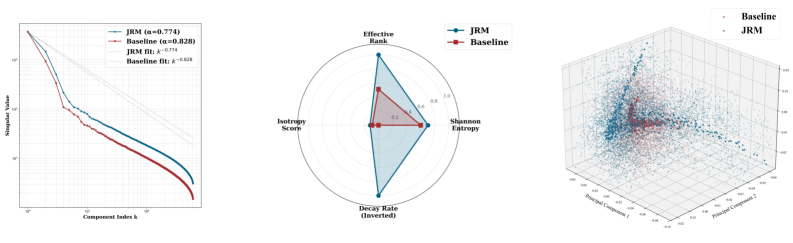
- Increases effective feature space rank to 91.77 (vs. 46.86 for baseline), indicating prevention of representation collapse
Breakthrough Assessment
9/10
Proposes a paradigm shift that successfully bridges the efficiency of discriminative models with the reasoning depth of generative models, backed by SOTA results against future baselines like GPT-5.