📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Model Evaluation
Mathematical Reasoning
RewardMATH is a new benchmark that evaluates the robustness of math reward models by using one-to-many comparisons against diverse incorrect solutions, correlating better with downstream policy performance than existing benchmarks.
Core Problem
Existing reward model benchmarks like RewardBench rely on one-to-one comparisons and human-written chosen solutions that differ distributionally from model outputs, making them unreliable indicators of true robustness.
Why it matters:
- Reward models susceptible to 'reward hacking' may score high on benchmarks but degrade policy performance during RLHF due to overoptimization.
- Current benchmarks fail to predict how well a reward model will actually guide a policy, leading to wasted compute on ineffective alignment.
Concrete Example:
In RewardBench, a human-written 'chosen' solution might skip steps (mental math), while a model-generated 'rejected' solution is verbose. A reward model might learn to prefer short answers (length bias) rather than correctness. Additionally, a model might correctly reject one specific wrong answer but fail against 8 other subtle wrong answers.
Key Novelty
RewardMATH Benchmark
- Replaces human-written 'chosen' solutions with correct step-by-step machine-generated solutions to match the distribution of rejected responses, removing length/style confounding factors.
- Employs a one-to-many comparison setting (1 correct vs. 9 incorrect solutions from various models) to rigorously test if the reward model can distinguish the correct answer from a diverse set of errors, rather than just one isolated failure case.
Architecture
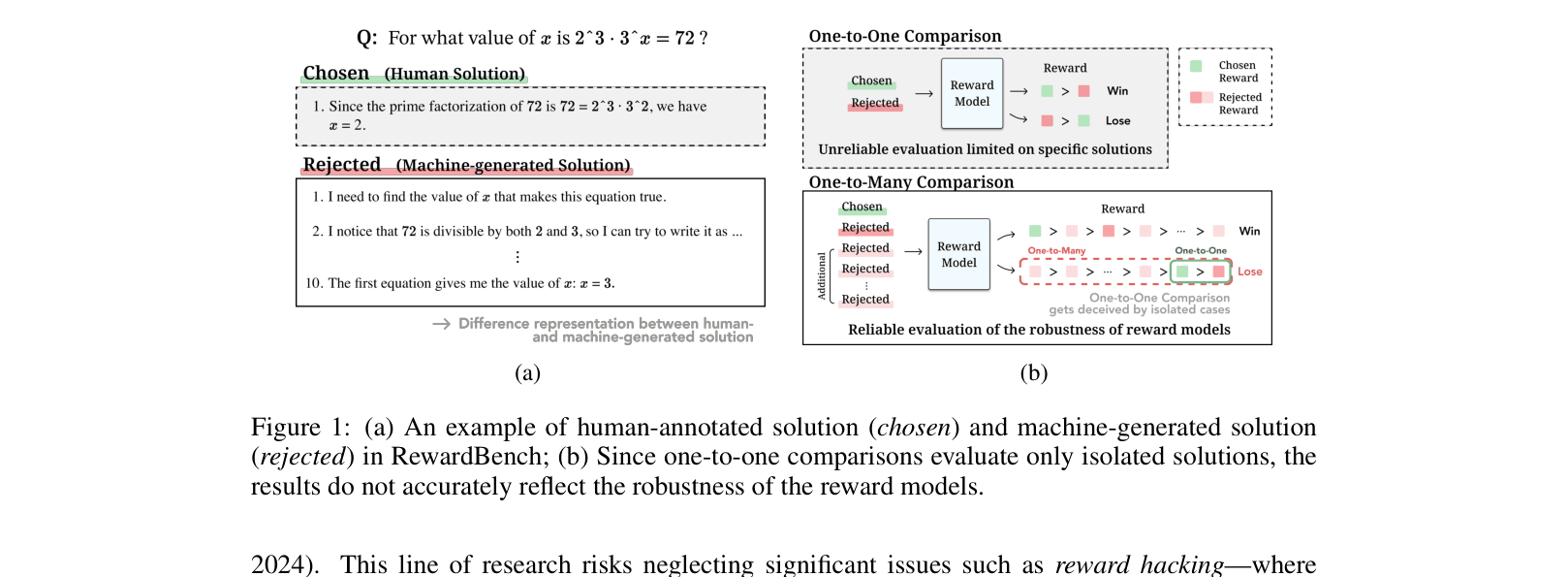
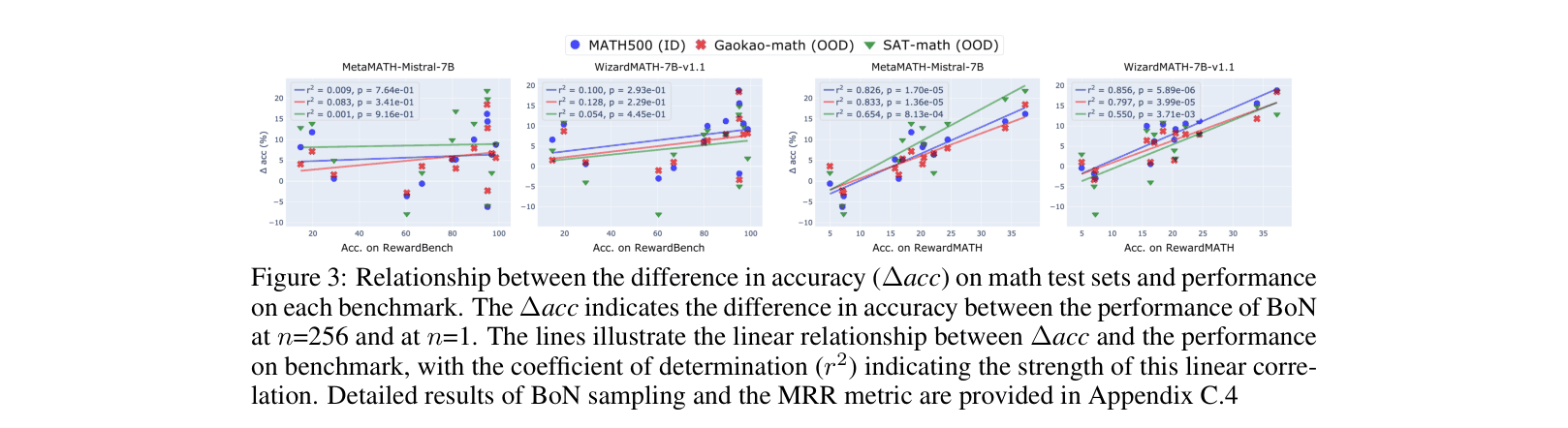
Contrast between RewardBench (1-vs-1, Human vs Model) and RewardMATH (1-vs-9, Model vs Model).
Evaluation Highlights
- Scores on RewardMATH strongly correlate (r² > 0.8) with the performance of policies optimized via Best-of-N sampling, whereas RewardBench shows almost no correlation (r² < 0.13).
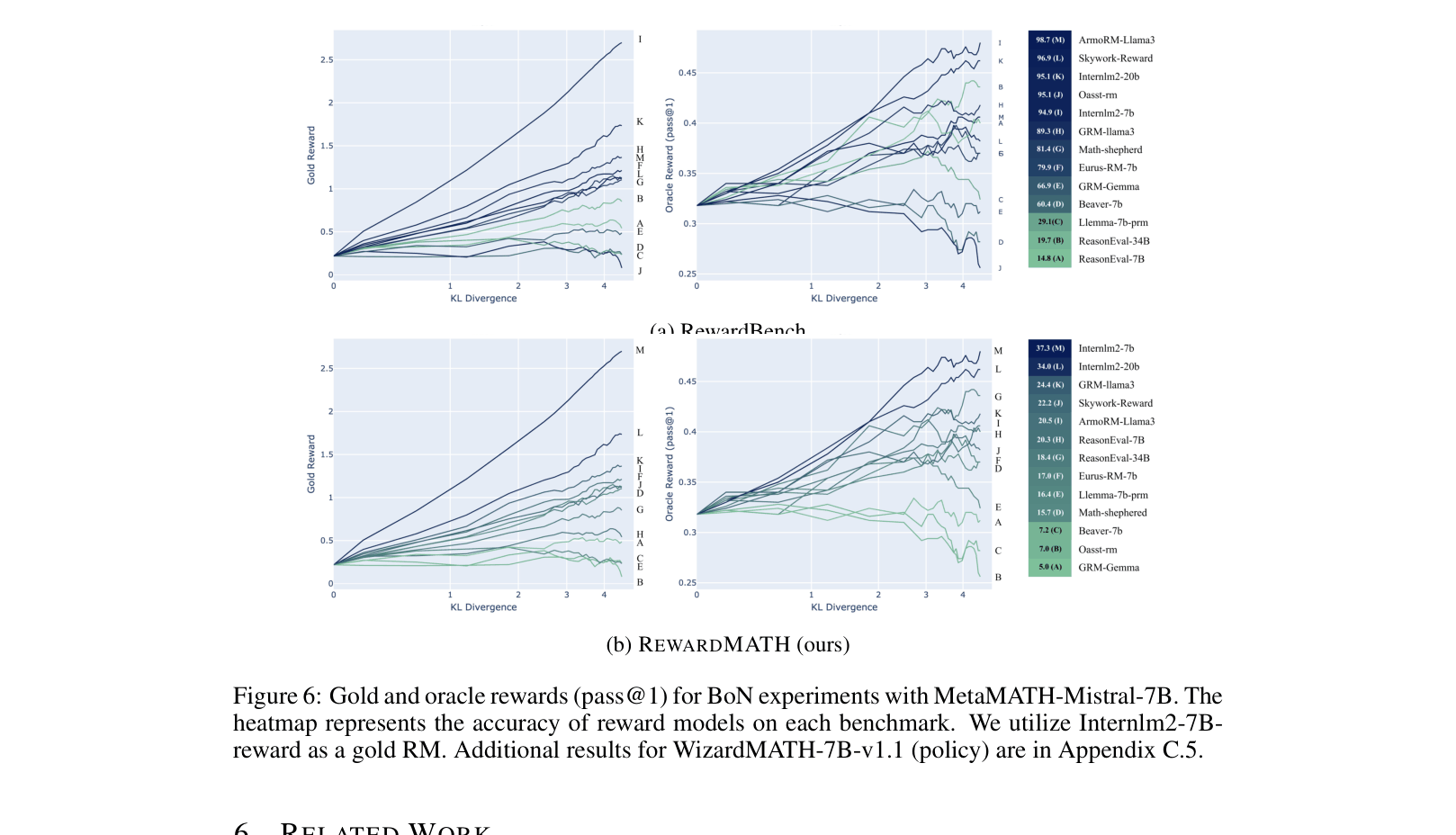
- Top-ranked RewardBench models (e.g., Oasst-rm-2.1) often perform poorly on RewardMATH and suffer rapid reward overoptimization in downstream tasks.
- RewardMATH effectively predicts resistance to reward overoptimization: models with higher RewardMATH scores maintain oracle performance (pass@1) longer as KL divergence increases.
Breakthrough Assessment
8/10
Identifies a critical flaw in current RM evaluation (distribution shift and sparsity of comparisons) and provides a significantly more predictive benchmark for actual RLHF outcomes.