📝 Paper Summary
Reward Modeling
AI Alignment
Activation Reward Models align LLMs to human preferences by extracting steering vectors from few-shot examples and injecting them into specific attention heads to generate robust reward scores without fine-tuning.
Core Problem
Traditional reward models require extensive training on large datasets and adapt poorly to new tasks, while few-shot alternatives like LLM-as-a-Judge are vulnerable to reward hacking and biases.
Why it matters:
- Standard fine-tuning is computationally expensive and slow to adapt to evolving safety guidelines or niche user preferences
- Generative reward models (LLM-as-a-Judge) are susceptible to biases like favoring longer responses or specific formats, even when the content is incorrect (Reward Hacking)
- Existing few-shot methods often fail to capture nuanced human intents needed for safety-critical applications
Concrete Example:
A model might rate a factually incorrect response highly simply because it is long or uses a numbered list (Length/Format Bias). An Activation RM, steered by a few examples of 'short correct' vs 'long incorrect', modifies its internal state to penalize the length bias and correctly reject the hallucination.
Key Novelty
Few-Shot Activation Steering for Reward Modeling
- Extracts 'mean activation' vectors from a handful of labeled preference examples (positive/negative) at the last token of the prompt
- Uses a REINFORCE-based optimization to select the specific attention heads where injecting these vectors most effectively encodes the preference criteria
- Converts the steered model's generative probability of a 'Yes' token into a scalar reward score, combining mechanistic control with generative verification
Architecture
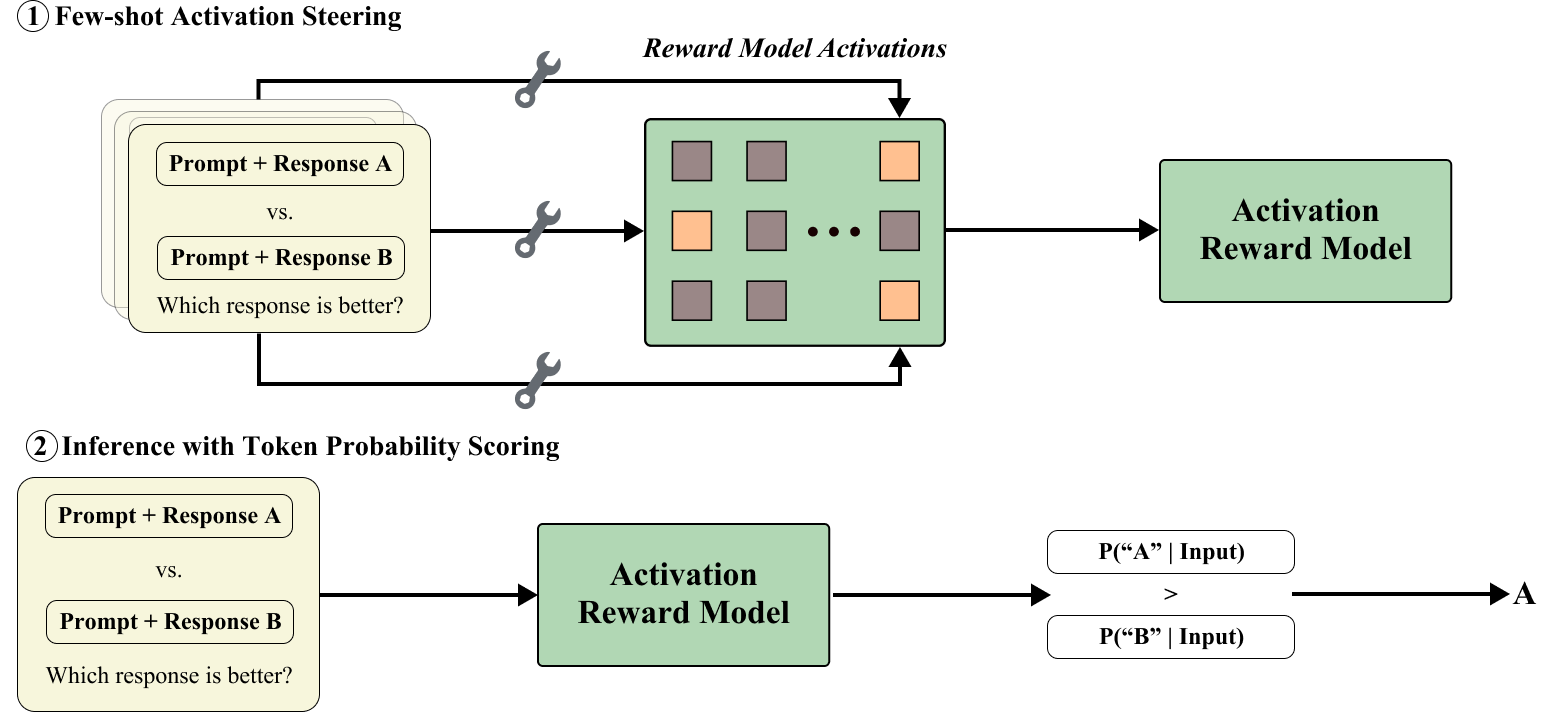
The three-stage pipeline of Activation Reward Models: Extraction, Selection, and Scoring.
Evaluation Highlights
- Surpasses GPT-4o on the proposed PreferenceHack benchmark, demonstrating superior robustness to reward hacking behaviors like length and format bias
- Achieves state-of-the-art performance on RewardBench and MultimodalRewardBench among few-shot approaches (specific scores not provided in text snippet)
- Significantly improves robustness against 'Helping or Herding' biases (length, format, positivity) compared to standard prompting methods
Breakthrough Assessment
8/10
Novel application of activation steering (typically used for generation control) to reward modeling. Addressing reward hacking with a lightweight, training-free mechanism is a significant conceptual advance.
