📝 Paper Summary
Inverse Reinforcement Learning (IRL)
Diffusion Models for Decision Making
AI Safety and Interpretability
The paper extracts reward functions by training a neural network to align its gradients with the difference in score outputs between an expert diffusion model and a suboptimal base diffusion model.
Core Problem
Extracting reward functions (Inverse Reinforcement Learning) typically requires environment access, simulators, or expensive iterative policy optimization loops, which are computationally heavy and difficult to apply to diffusion models.
Why it matters:
- Learning rewards allows for better robustness and generalization compared to simple imitation learning.
- Extracting rewards helps in auditing and interpreting AI behavior (e.g., identifying biases or harmful preferences in large generative models).
- Current MaxEnt IRL (Maximum Entropy Inverse Reinforcement Learning) methods assume access to the environment to train the policy, which is not always feasible.
Concrete Example:
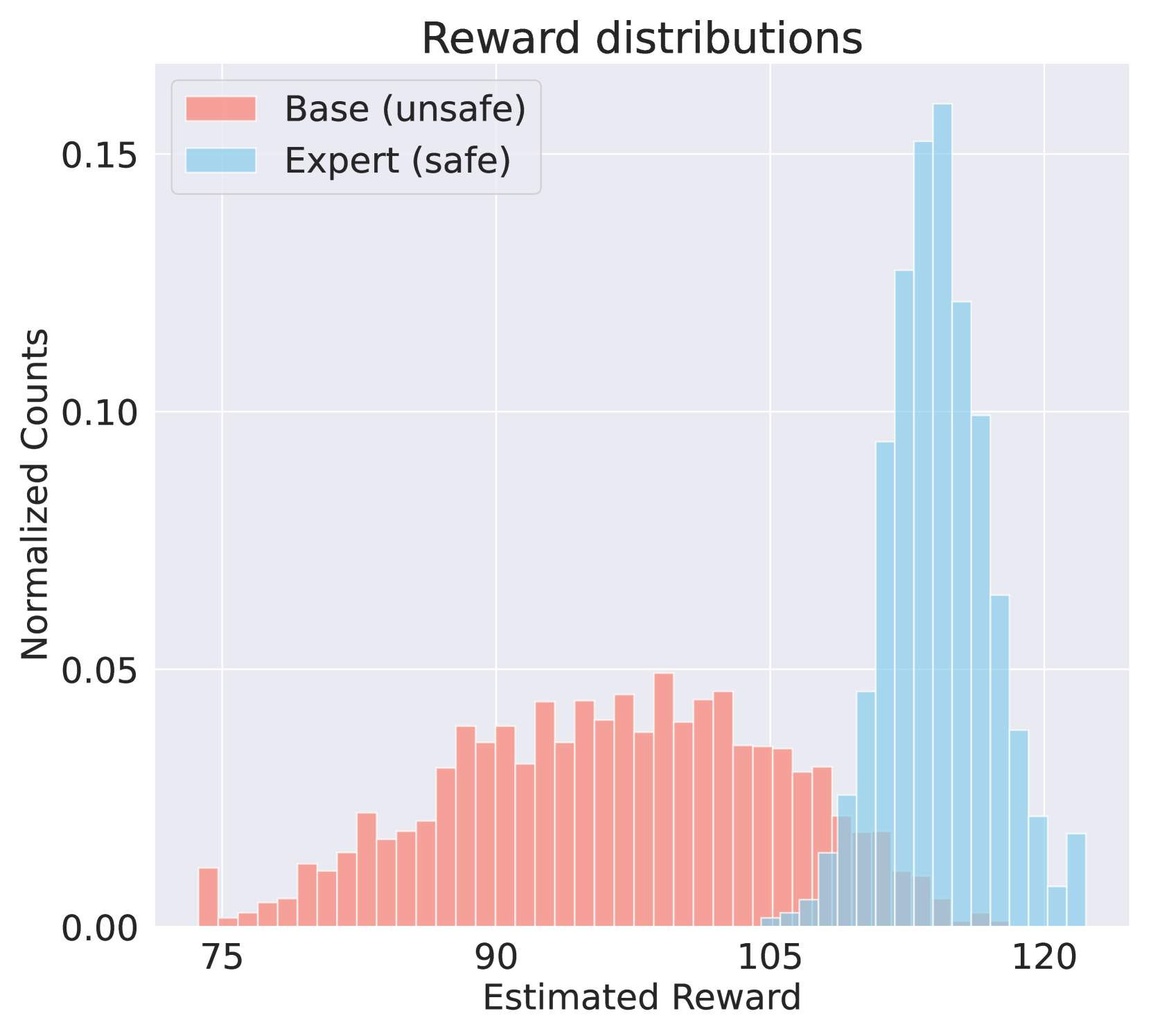
When analyzing a large image generation model, it is difficult to explicitly identify its biases. By comparing a standard model to a 'safe' version, this method extracts a reward function that explicitly assigns low scores to harmful content (violence/hate) without needing labeled classifiers.
Key Novelty
Relative Reward Extraction via Score Difference
- Defines a 'relative reward function' that explains the difference in probability distributions between two diffusion models (e.g., an expert and a base model).
- Extracts this reward by training a network to match the difference between the 'scores' (gradients of the log-density) of the expert and base diffusion models.
- Avoids the need for iterative policy updates or environment interaction, leveraging the steerability of diffusion models.
Architecture
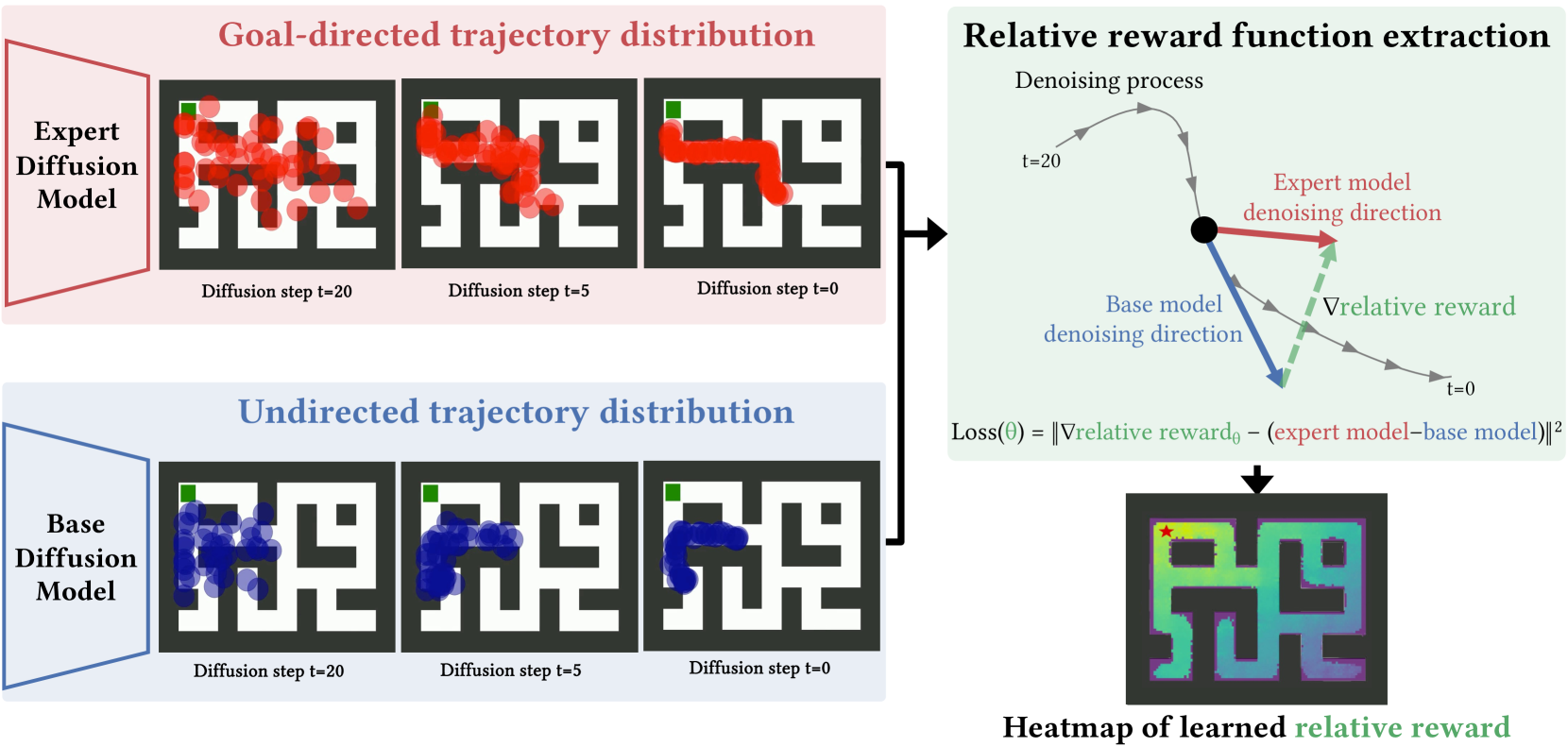
Illustration of the method extracting a relative reward function from two decision-making diffusion models.
Evaluation Highlights
- Successfully recovers ground-truth reward functions (distance maps) in Maze2D navigation environments by comparing exploratory and goal-directed diffusion models.
- Steering a low-quality base diffusion model with the learned reward function results in significantly increased performance on standard locomotion benchmarks (Hopper, HalfCheetah, Walker2D).
- Generalizes to image generation by extracting a reward function that penalizes harmful content when comparing Stable Diffusion to a 'safer' version.
Breakthrough Assessment
7/10
Proposes a mathematically grounded and computationally efficient method for IRL with diffusion models. It removes the need for environment interaction, which is a significant theoretical and practical advantage, though relies on having two distinct pre-trained models.