📊 Experiments & Results
Evaluation Setup
Multimodal Reward Modeling Benchmarks
Benchmarks:
- VL Reward-Bench (Visual-Language Preference Evaluation)
- Multimodal Reward Bench (Multimodal Preference Evaluation)
- MM-RLHF Reward Bench (RLHF Preference Evaluation)
Metrics:
- Accuracy (Preference Matching)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| The paper reports significant relative improvements over SOTA across three benchmarks. (Absolute values for baselines were not extractable from the provided text snippet, so only the delta is described qualitatively in takeaways). | ||||
Experiment Figures
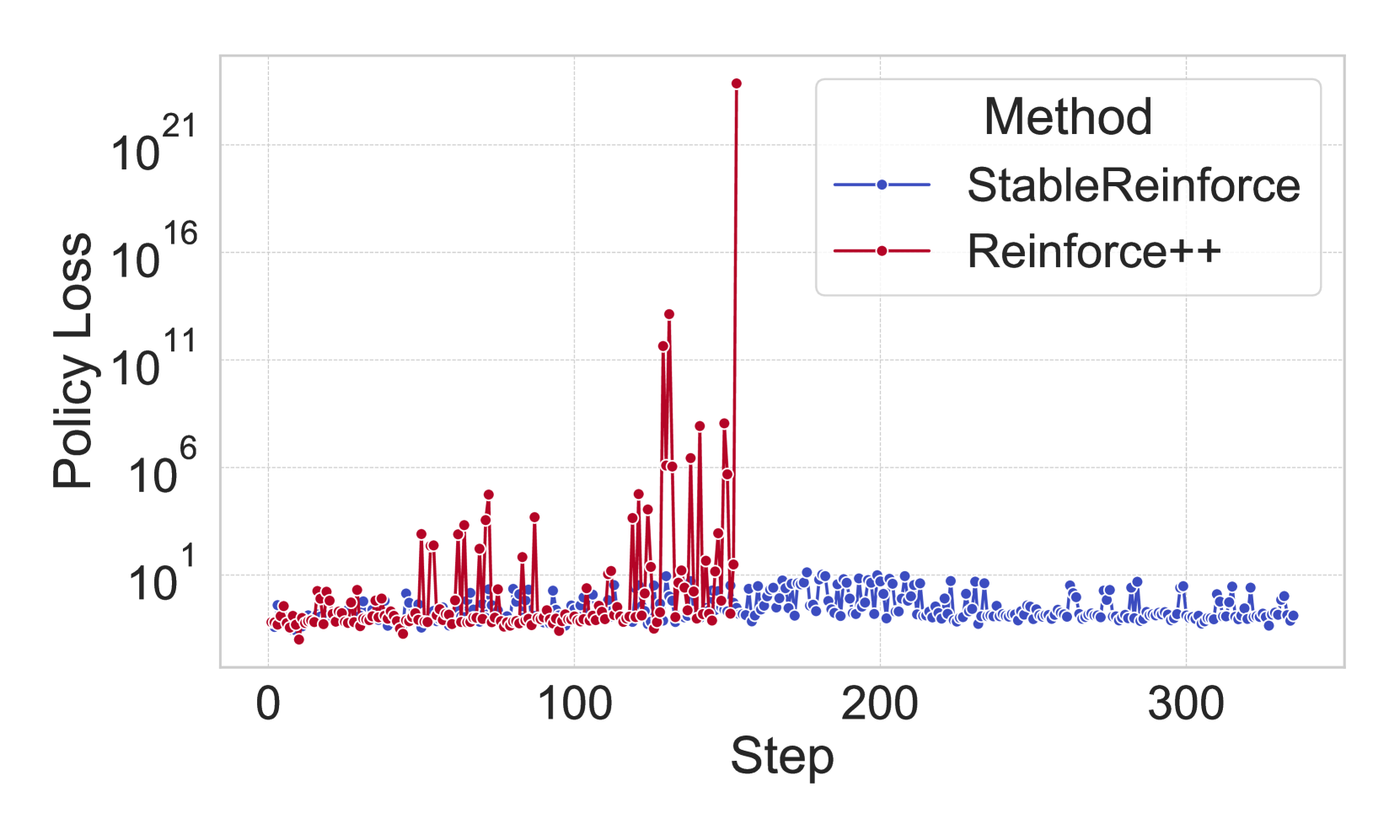
Effect of the reinforcement learning phase on token compression and performance.
Main Takeaways
- R1-Reward achieves consistent improvements over state-of-the-art models on all three tested benchmarks (VL Reward-Bench, Multimodal Reward Bench, MM-RLHF Reward Bench).
- Inference-time scaling (Best-of-N, specifically sampling 5 times) significantly boosts performance, raising improvement on VL Reward-Bench from 8.4% to 13.5%.
- The 'StableReinforce' algorithm successfully stabilizes training where traditional PPO and Reinforce++ fail due to binary reward distributions and policy divergence.
- Filtering training data by difficulty (using GPT-4o sampling attempts) is effective; the model benefits from focusing on 'hard' samples where reasoning is most needed.