📝 Paper Summary
Reinforcement Learning for LLMs
Reasoning
PRIME enables efficient online reinforcement learning for reasoning by deriving dense token-level process rewards from outcome labels, eliminating the need for expensive step-by-step human annotations.
Core Problem
Training Process Reward Models (PRMs) typically requires expensive step-level annotations, and using static PRMs leads to reward hacking (overoptimization) during online RL.
Why it matters:
- Sparse outcome rewards (only rewarding the final answer) are inefficient for complex multi-step reasoning tasks and suffer from credit assignment issues
- Existing methods to get dense rewards rely on costly human labeling pipelines or inaccurate estimation methods that require massive computational overhead
- Current industry-leading models rely on outcome rewards because scalable, high-quality dense reward acquisition remains unsolved
Concrete Example:
In a complex math problem, a model might use incorrect logic but accidentally arrive at the correct final answer. Standard outcome-based RL rewards this spurious trajectory positively. A static PRM might catch the error initially, but as the policy shifts during training, it exploits flaws in the fixed reward model (reward hacking), leading to high scores but nonsense reasoning.
Key Novelty
Process Reinforcement through Implicit Rewards (PRIME)
- Updates the Process Reward Model (PRM) online using only policy rollouts and outcome labels (correct/incorrect), bypassing the need for step-level annotations
- Calculates rewards 'implicitly' by measuring the drift between the online PRM and a reference model, providing dense token-level feedback without explicit step definitions
- Integrates these dense implicit rewards with sparse outcome rewards into a unified advantage estimation framework compatible with algorithms like PPO and RLOO
Architecture
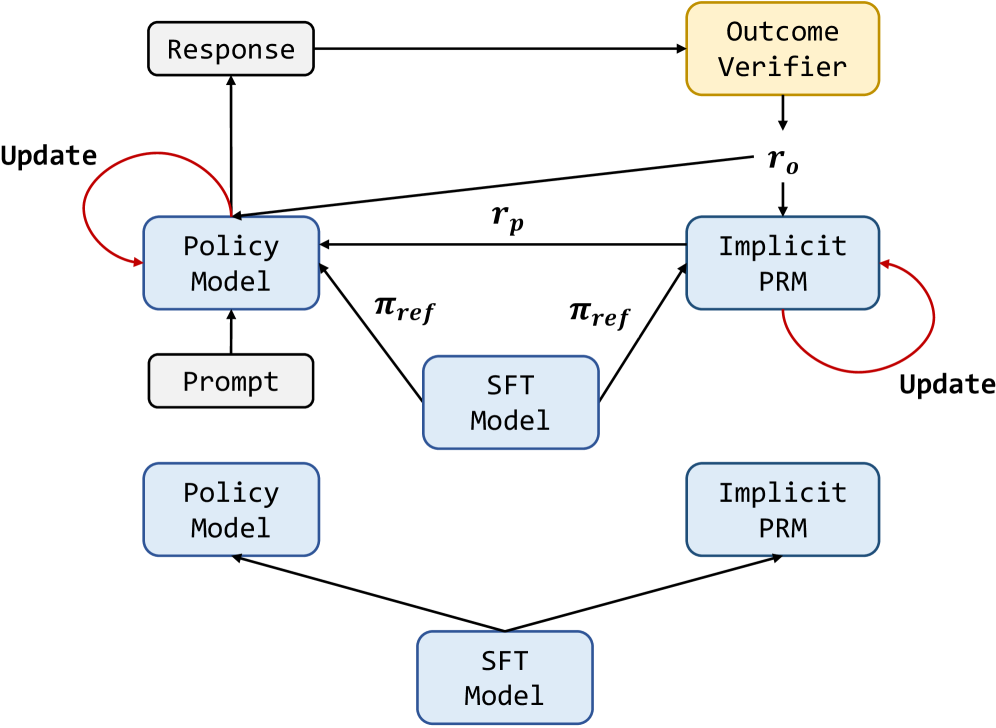
The PRIME framework workflow, illustrating the interaction between the Policy Model, Implicit PRM, and Outcome Verifier.
Evaluation Highlights
- +15.1% average improvement across seven reasoning benchmarks (including AIME and MATH-500) compared to the SFT (Supervised Fine-Tuning) baseline
- Achieves 26.7% Pass@1 on AIME 2024, surpassing GPT-4o and Qwen2.5-Math-7B-Instruct despite using only 10% of the instruction tuning data
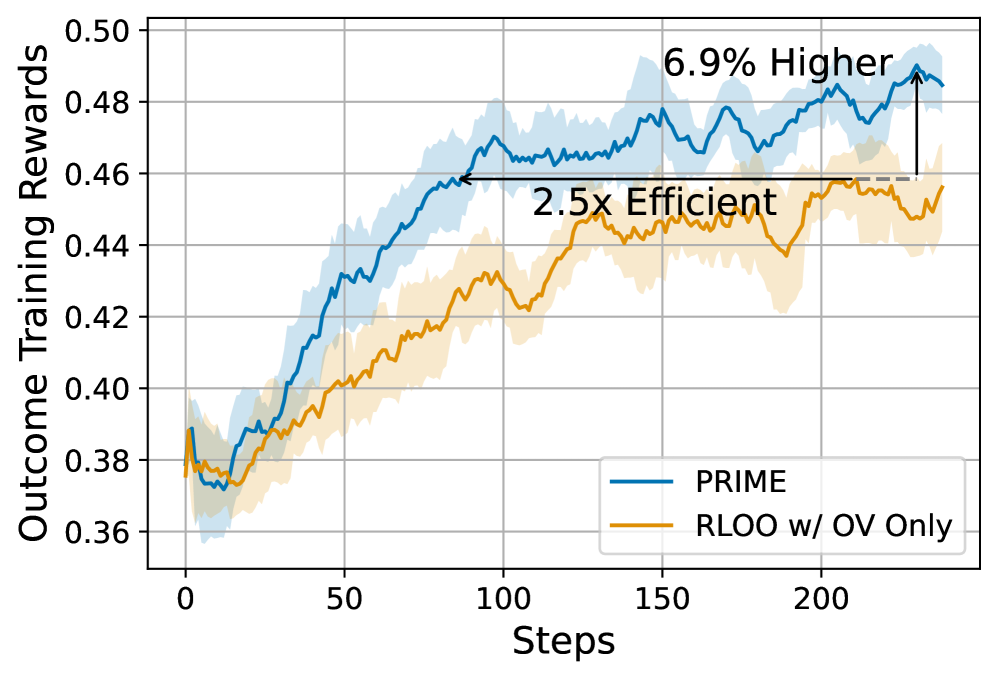
- Improves sample efficiency by 2.5x compared to Reinforcement Learning with Leave-One-Out (RLOO) using outcome rewards only
Breakthrough Assessment
9/10
Offers a scalable solution to the 'Process Reward' bottleneck by removing the need for step-by-step labels. The efficiency gains and performance vs. established baselines (like Qwen-Math) with significantly less data suggest a major methodological advance.