📝 Paper Summary
Reward Modeling
RLHF (Reinforcement Learning from Human Feedback)
Data Curation
Skywork-Reward demonstrates that a small, high-quality, publicly sourced dataset (80K pairs) combined with standard Bradley-Terry loss yields state-of-the-art reward models, outperforming models trained on much larger datasets.
Core Problem
Open-source preference datasets for training reward models are often noisy, inconsistent, or excessively large, leading to suboptimal model alignment.
Why it matters:
- High-quality reward models are critical for aligning LLMs via RLHF, acting as evaluators for fine-tuning and deployment
- Current approaches often rely on massive, noisy datasets (700K to millions of samples) or proprietary internal data, hindering reproducibility and efficiency
- Inconsistently labeled preference pairs can degrade reward model performance by introducing conflicting signals
Concrete Example:
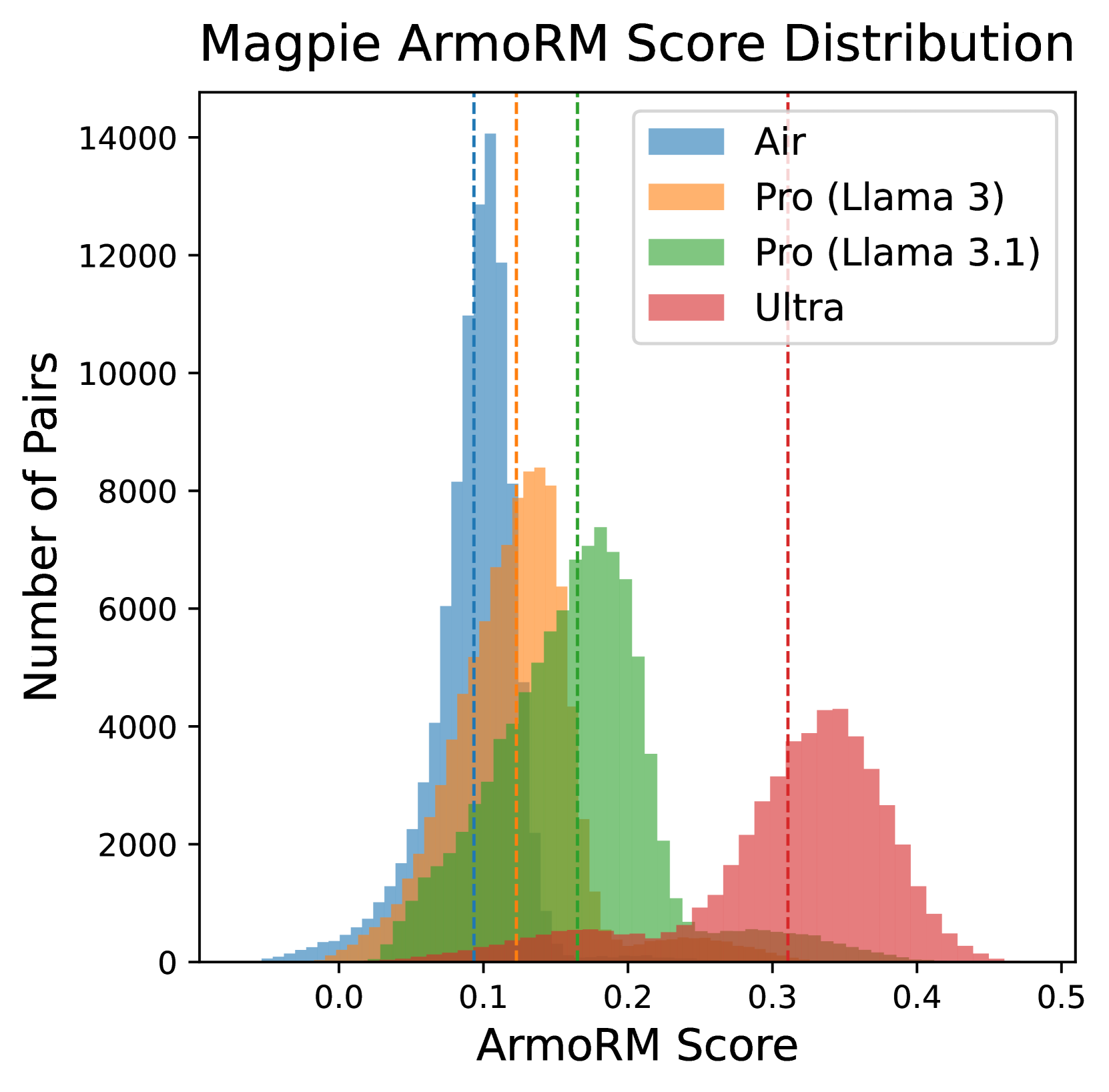
In the Magpie dataset, responses from smaller models (Llama-3-8B) sometimes receive higher ArmoRM scores than those from larger models (Llama-3-70B) due to bias. Without filtering or adjustment, training on these noisy labels confuses the reward model about true response quality.
Key Novelty
Data-Centric Reward Modeling Curation (Skywork-Reward)
- Constructs a lightweight dataset (80K pairs) solely from public sources by aggressively filtering for high-quality, hard samples (e.g., math/code focus) and adversarial safety examples
- Implements a two-stage filtering process for adversarial safety data: first removing easy pairs the model already gets right, then keeping only hard pairs the model handles correctly to balance safety and general performance
- Demonstrates that simple Bradley-Terry loss outperforms complex margin-based or focal loss variants when data quality is sufficiently high
Architecture
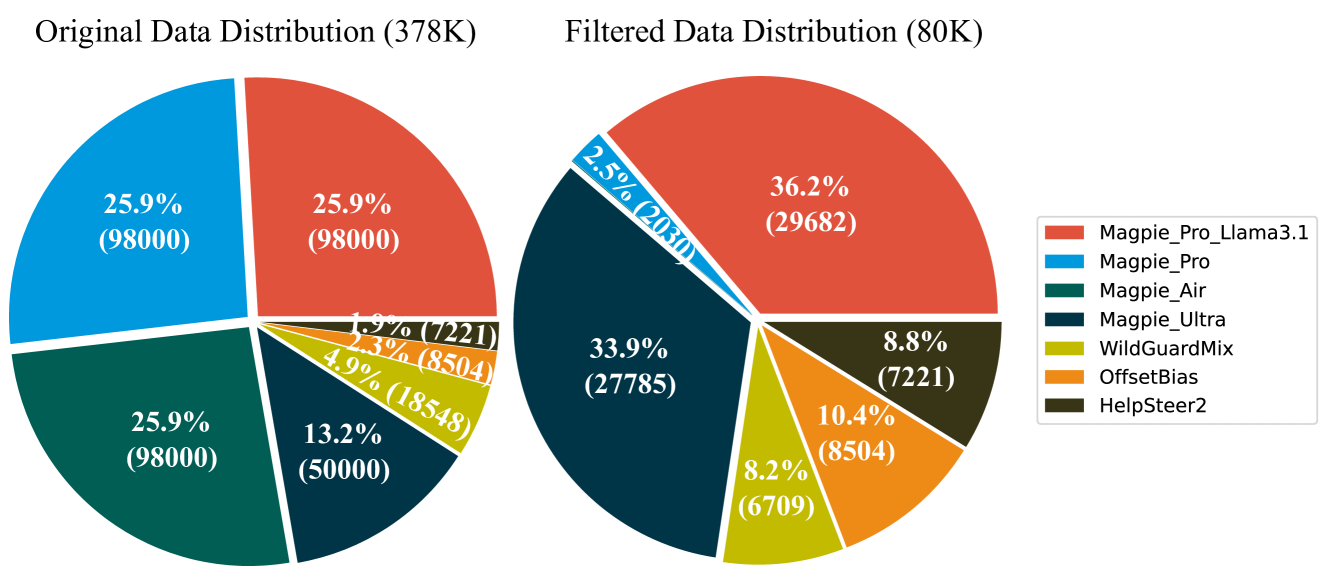
Composition of the Skywork-Reward-Preference-80K dataset
Evaluation Highlights
- Skywork-Reward-Gemma-27B achieves 1st place on the RewardBench leaderboard (as of Oct 2024), outperforming proprietary and much larger models
- Skywork-Reward-Llama-3.1-8B achieves 7th place on RewardBench, demonstrating high efficiency for its size
- The curated 80K dataset achieves these results despite being <12% the size of typical aggregation datasets (e.g., 700K+ samples used in prior work)
Breakthrough Assessment
8/10
Significant for achieving SOTA on RewardBench with a fully open, reproducible, and small (80K) dataset, challenging the 'more data is better' trend and validating standard loss functions over complex ones.