📝 Paper Summary
Reward Design
Alignment
Reinforcement Learning
This paper enables users to train reinforcement learning agents on abstract objectives by using frozen large language models as proxy reward functions via natural language prompts.
Core Problem
Defining rewards for abstract human preferences (like 'versatility' or 'fairness') is difficult to encode mathematically and collecting large datasets for learned rewards is expensive.
Why it matters:
- Hand-crafting reward functions for complex behaviors is non-intuitive and prone to reward hacking, where agents exploit specification errors.
- Learning rewards typically requires large amounts of labeled expert data, which does not generalize to new users with different objectives.
- Existing methods like RLHF require fine-tuning models, which is computationally expensive compared to using frozen models.
Concrete Example:
A user wants a 'versatile' negotiation agent. Writing a mathematical formula for 'versatility' is hard. Collecting thousands of examples of versatile vs. non-versatile behavior is costly. Consequently, agents trained with standard rewards often fail to capture this nuance.
Key Novelty
LLM-as-a-Proxy-Reward (frozen prompting)
- Uses a frozen Large Language Model (LLM) as a reward function by prompting it with a task description, a few examples of desired behavior, and the agent's current action.
- Leverages the LLM's pre-trained commonsense priors about human behavior to perform zero-shot or few-shot evaluation of agent trajectories without fine-tuning.
Architecture
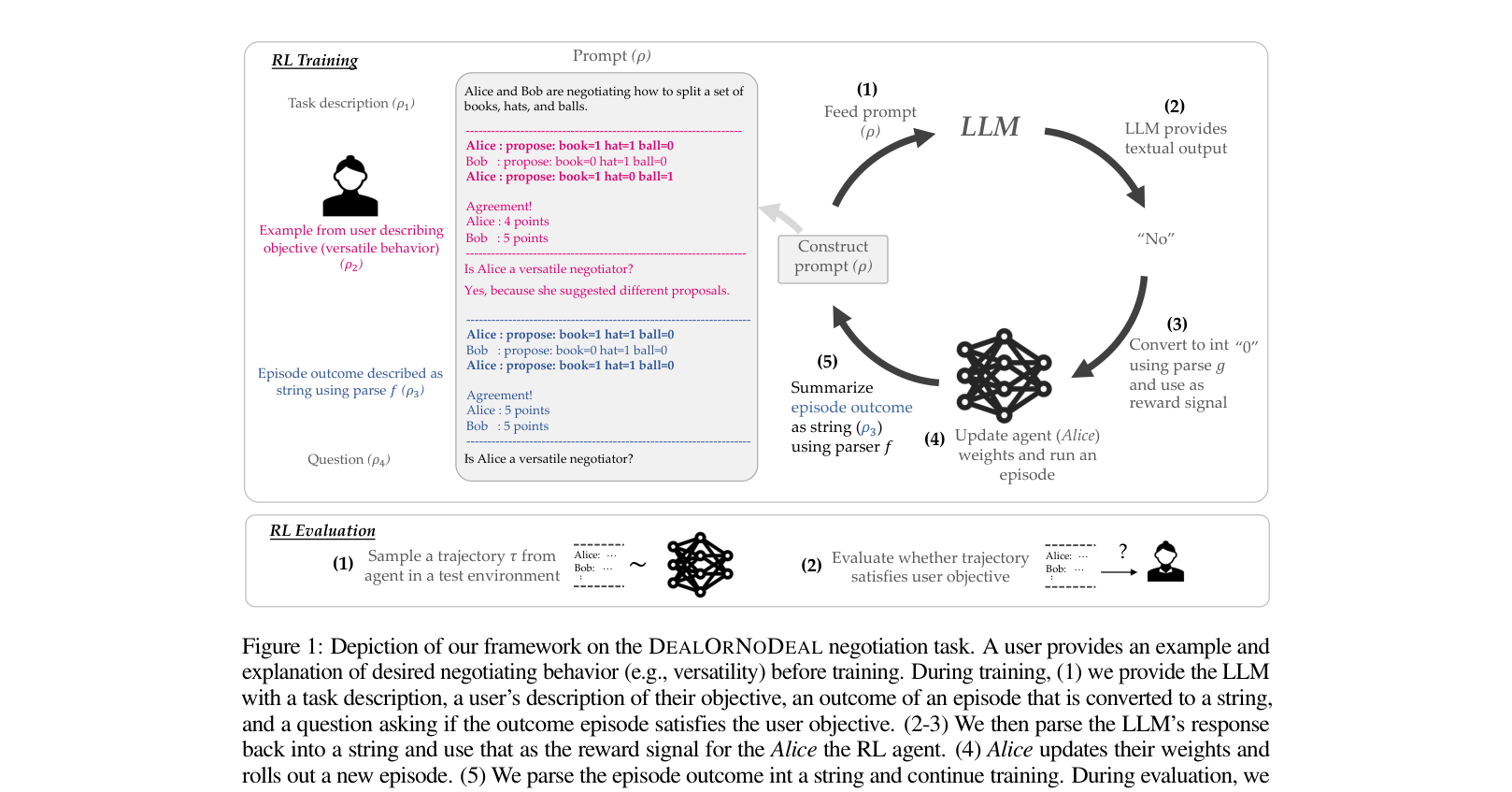
The RL training loop using an LLM as a proxy reward function. It illustrates how user prompts and episode outcomes are fed to the LLM to generate a binary reward.
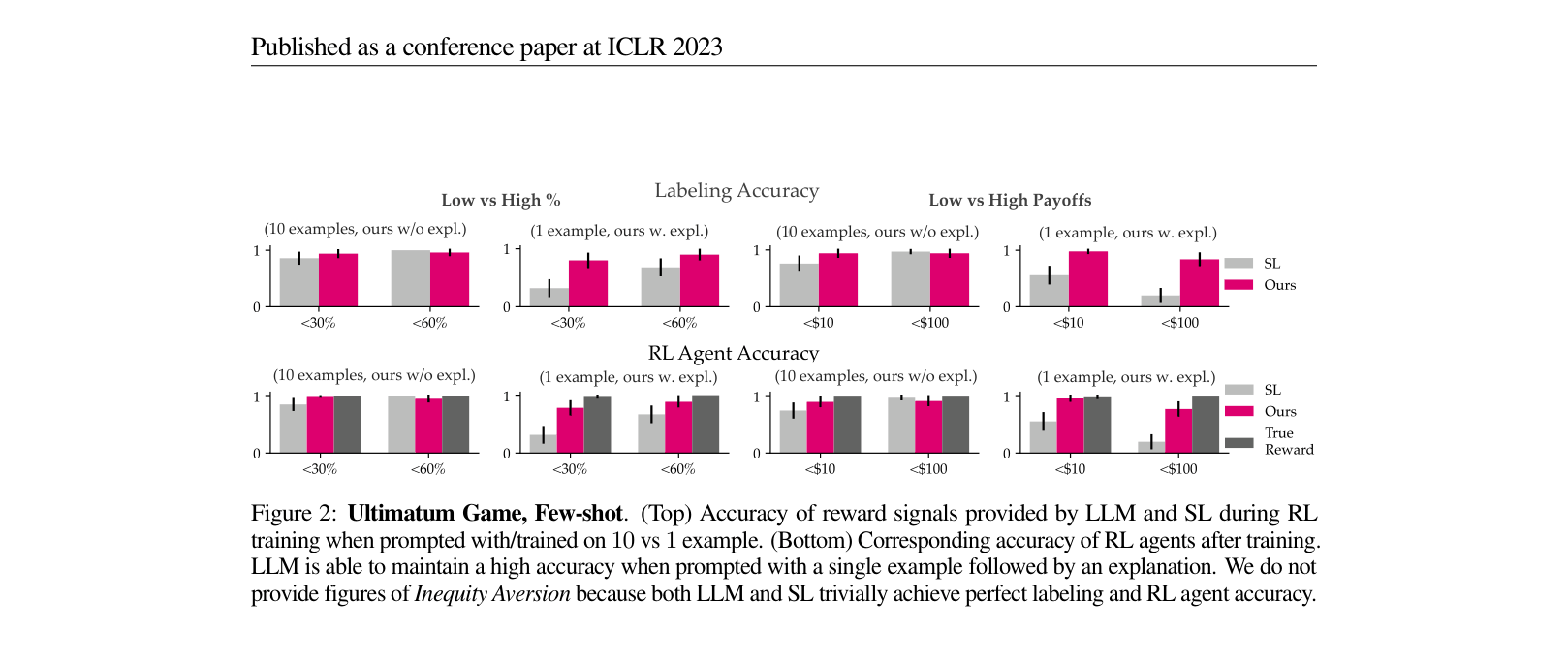
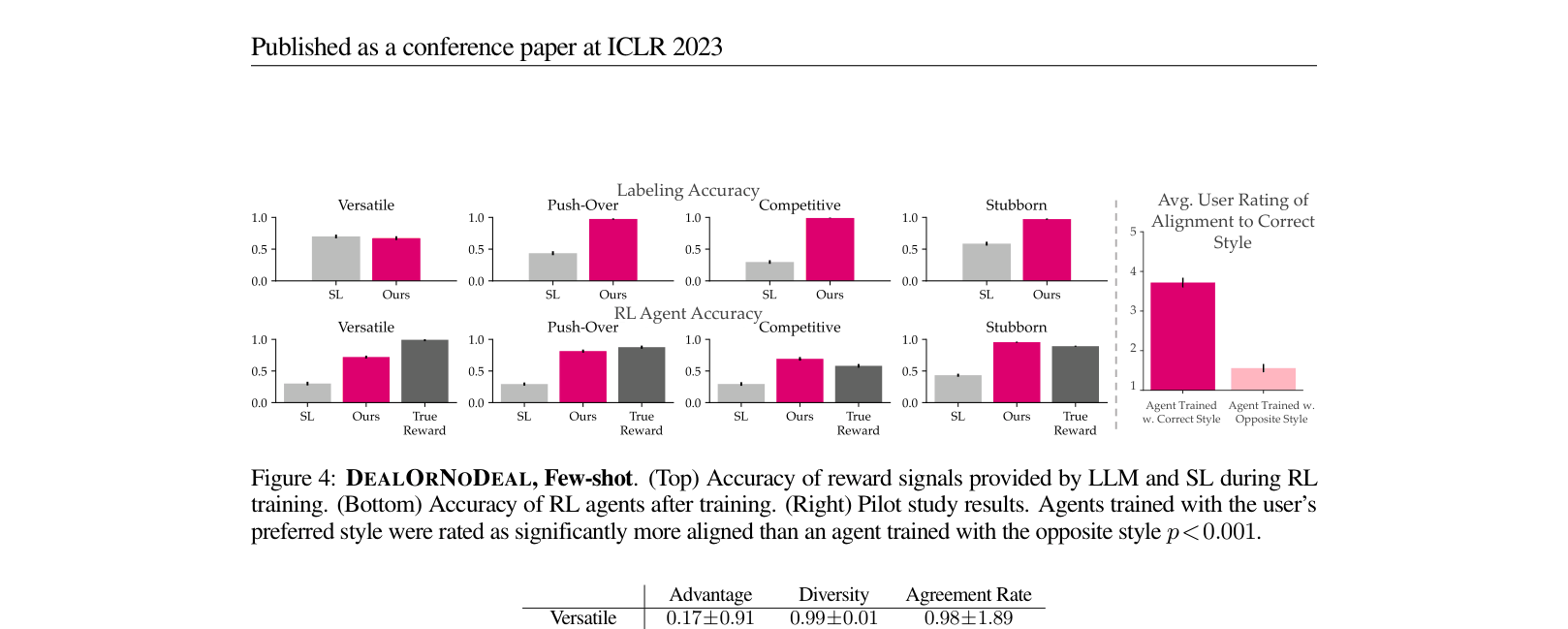
Evaluation Highlights
- Outperforms Supervised Learning (SL) baselines by an average of 46% in training objective-aligned agents for the complex DealOrNoDeal negotiation task.
- Achieves 3.72/5 user alignment rating in a human study, significantly higher than agents trained with opposite styles (1.56/5).
- Demonstrates zero-shot capability in Matrix Games, improving reward labeling accuracy by 48% over a 'No Objective' baseline.
Breakthrough Assessment
8/10
A significant step in democratizing reward design. It effectively replaces complex reward engineering with natural language prompting, showing strong empirical results across varying task complexities.