📝 Paper Summary
Reward Modeling
RLHF (Reinforcement Learning from Human Feedback)
BNRM replaces standard dense reward heads with a Bayesian non-negative layer that enforces sparsity to disentangle semantic preferences from spurious biases like response length.
Core Problem
Standard reward models in RLHF are deterministic and dense, making them prone to 'reward hacking' where they over-optimize spurious correlations (like length or style) rather than true human intent.
Why it matters:
- Reward over-optimization causes aligned models to generate gibberish or verbose nonsense that scores high on the proxy reward but fails user needs
- Current mitigation strategies like ensembles are computationally expensive, while supervised interventions generalize poorly
- Dense neural networks inherently exploit shortcut features, making it difficult to separate true semantic signals from noise without structural constraints
Concrete Example:
A policy might learn that longer responses always yield higher rewards because the reward model overfits to length bias in human annotations. Consequently, the model generates excessively wordy paragraphs for simple yes/no questions to 'hack' the score.
Key Novelty
Bayesian Non-Negative Reward Model (BNRM)
- Reinterprets reward modeling as a generative process where preferences arise from sparse, non-negative latent factors rather than dense projections
- Enforces two-level sparsity: local sparsity to disentangle instance-specific features (semantics) and global sparsity to suppress dataset-wide spurious correlations (biases)
- Uses amortized variational inference with Weibull distributions to efficiently train these probabilistic layers on top of standard LLM backbones
Architecture
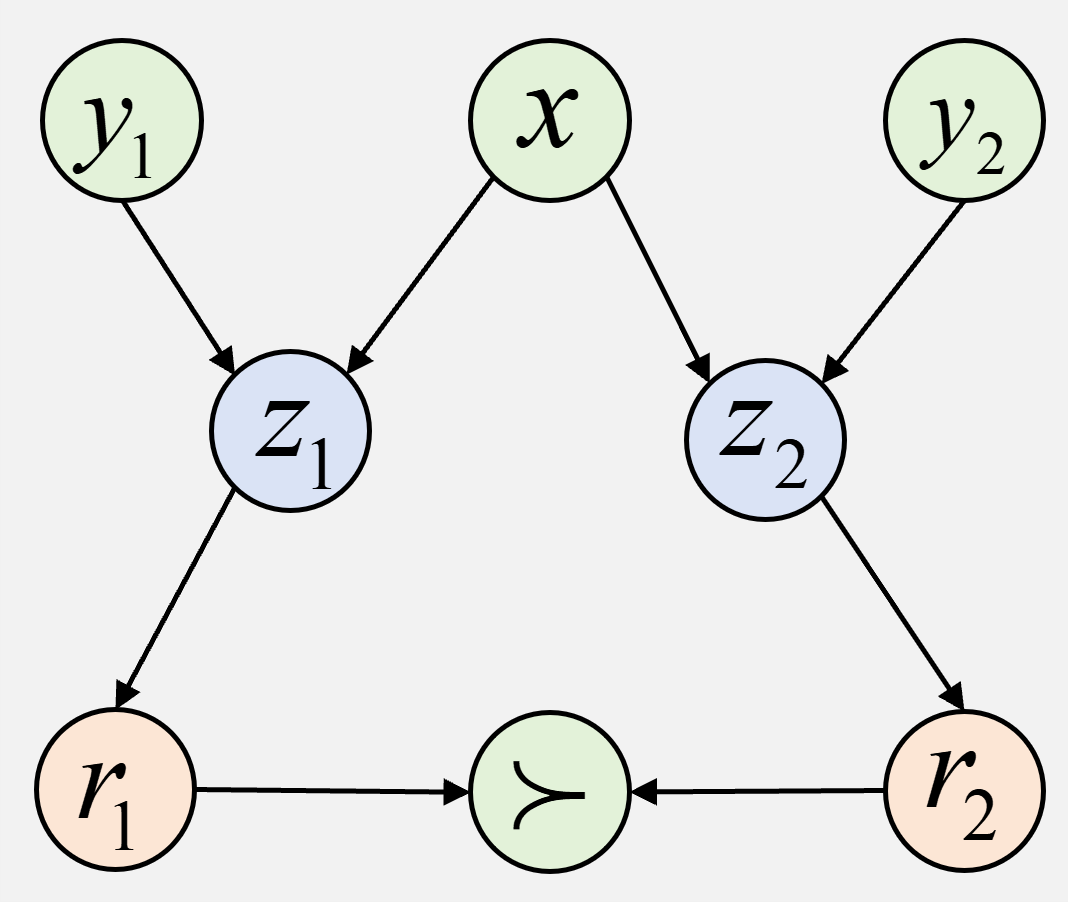
The amortized variational inference framework for BNRM
Breakthrough Assessment
7/10
Proposes a principled, structural fix to reward hacking via NFA (Non-negative Factor Analysis) integration, moving beyond band-aid solutions like regularization or ensembles.