📊 Experiments & Results
Evaluation Setup
Zero-shot evaluation of RMs on multiple-choice survey and bias datasets
Benchmarks:
- OpinionQA (Public opinion survey (ordinal))
- PRISM (Demographic preference conversation)
- BBQ (Bias and Stereotype detection)
- StereoSet (Stereotype detection)
Metrics:
- Alignment Metric (1 - Normalized Distance)
- Friedman Test Statistic
- Spearman's Rank Correlation
- Effect Size (Wilcoxon signed-rank test)
- Statistical methodology: Friedman test for group rank differences; Wilcoxon signed-rank test for steering effects; Benjamini-Hochberg correction for multiple tests
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Absolute alignment scores on PRISM show that model size/choice dominates alignment quality over demographic factors. | ||||
| PRISM | Alignment (JSD-based) | 0.732 | 0.930 | +0.198 |
| Steerability analysis reveals that in-context prompting has statistically negligible effects on RM behavior. | ||||
| OpinionQA | Effect Size (Wilcoxon) | 0.0 | 0.086 | +0.086 |
| OpinionQA | Effect Size (Wilcoxon) | 0.0 | 0.148 | +0.148 |
| Relative alignment analysis shows models strongly agree on which demographic groups they prefer, regardless of model architecture. | ||||
| OpinionQA | Spearman's Rank Correlation | 0 | 0.67 | +0.67 |
| OpinionQA | Friedman Test Statistic | 0 | 295.7 | +295.7 |
Experiment Figures

Average rank of alignment across demographic groups in OpinionQA
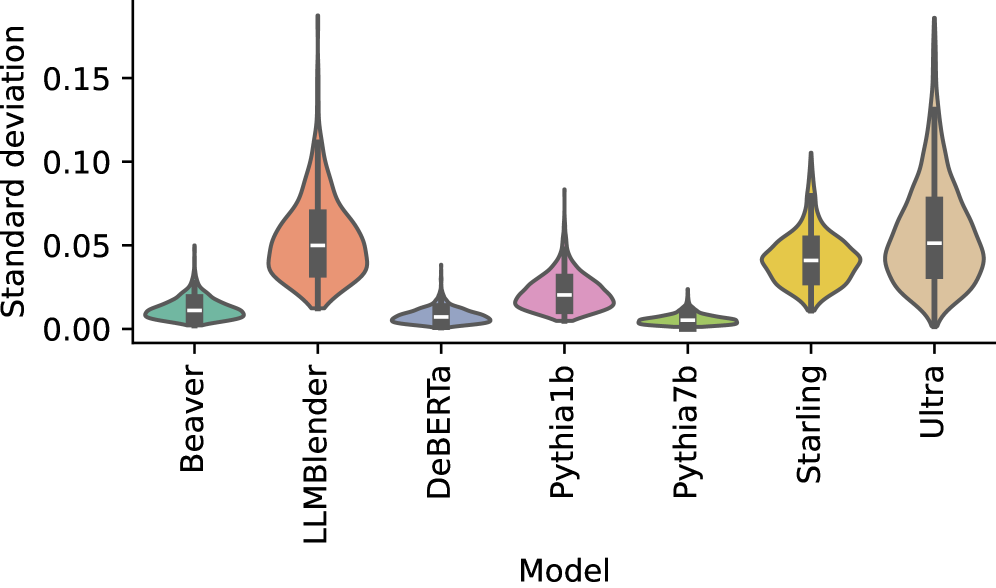
Standard deviations of alignment values across steering prompts
Main Takeaways
- Absolute alignment is driven by the specific RM chosen (better models align better with everyone), but relative alignment is structurally biased: RMs consistently favor the American South / lower education demographics over others.
- Steering via prompting (Bio, Portray, QA) is ineffective for RMs; unlike LMs, RMs do not meaningfully shift their reward distributions based on context.
- Stereotype behavior is inconsistent across models: some (UltraRM) prefer stereotypes, others (BeaverRM) prefer refusals or non-stereotypes, suggesting safety profiles must be audited per-model.
- Smaller RMs (e.g., Pythia1B) often default to 'Unknown' or random preferences in bias benchmarks, likely due to a lack of semantic capability to understand the stereotype.