📝 Paper Summary
Reinforcement Learning from Human Feedback (RLHF)
Reward Modeling
Chain-of-Thought Reasoning
CLoud reward models improve preference modeling by generating a natural language critique of an assistant's response before predicting a scalar reward score, enabling explicit reasoning.
Core Problem
Traditional reward models act as simple classifiers that predict scores in a single forward pass, forcing them to reason implicitly about response quality without leveraging the generation capabilities of the underlying LLM.
Why it matters:
- Implicit reasoning limits the performance of reward models compared to methods that use reasoning traces (like LLM-as-a-Judge)
- Classic reward models often fail to capture nuanced preference signals that require step-by-step verification
- LLM-as-a-Judge offers interpretability but generally underperforms classic reward models on pairwise classification benchmarks
Concrete Example:
A classic reward model might score a math solution highly because it looks authoritative, failing to catch a subtle arithmetic error. A CLoud model would first generate a critique identifying the calculation mistake, then assign a lower score based on that explicit finding.
Key Novelty
Critique-out-Loud (CLoud) Reward Models
- Unifies classic reward modeling with LLM-as-a-Judge by training the model to first generate a critique (reasoning trace) and then predict a scalar reward conditioned on that critique
- Leverages 'inference-time compute' for reward modeling: allows the model to think before it scores, improving accuracy via Chain-of-Thought-style processing
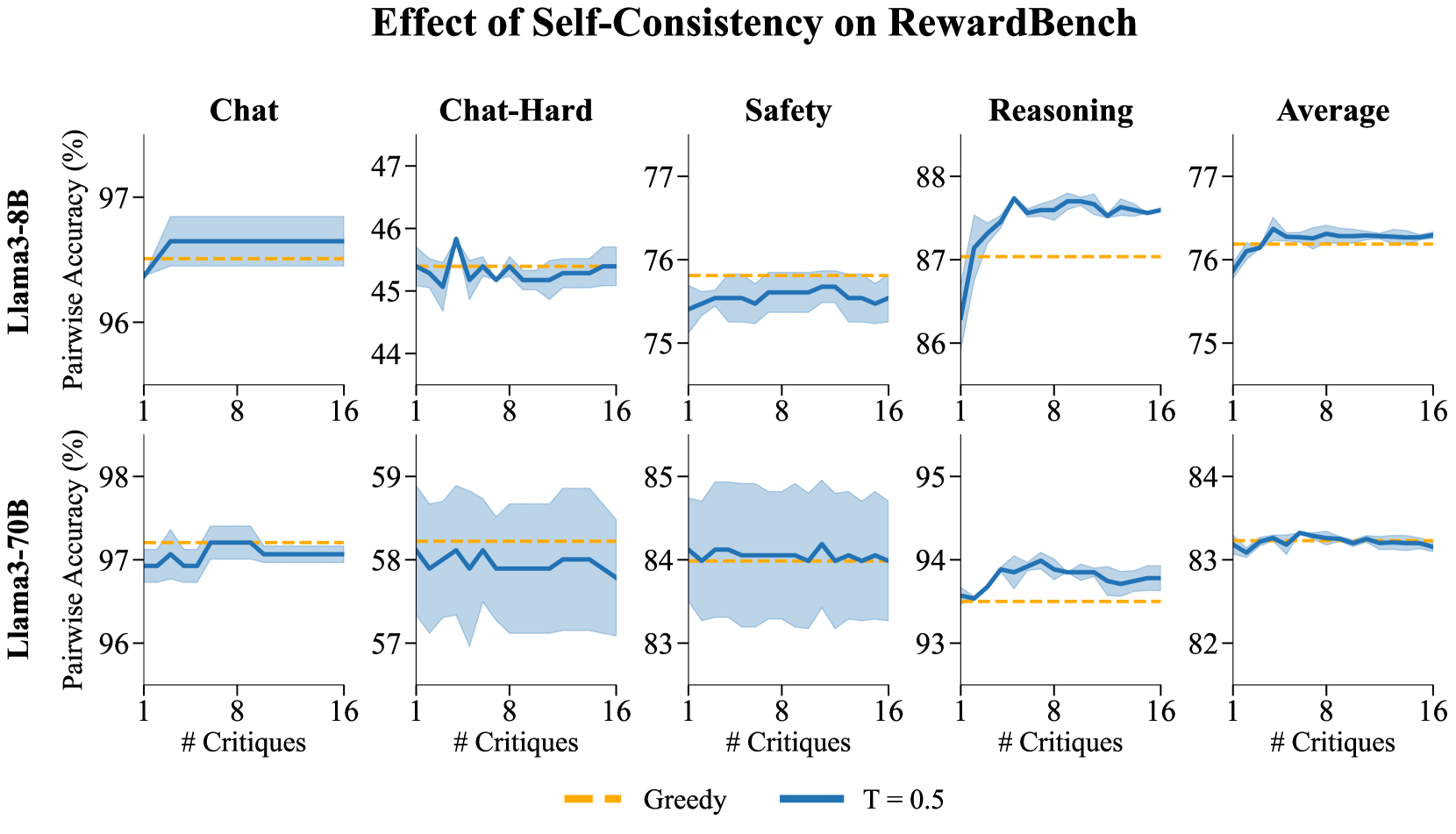
- Enables self-consistency over critiques: sampling multiple critiques and averaging the resulting scores to improve reward estimation stability
Architecture
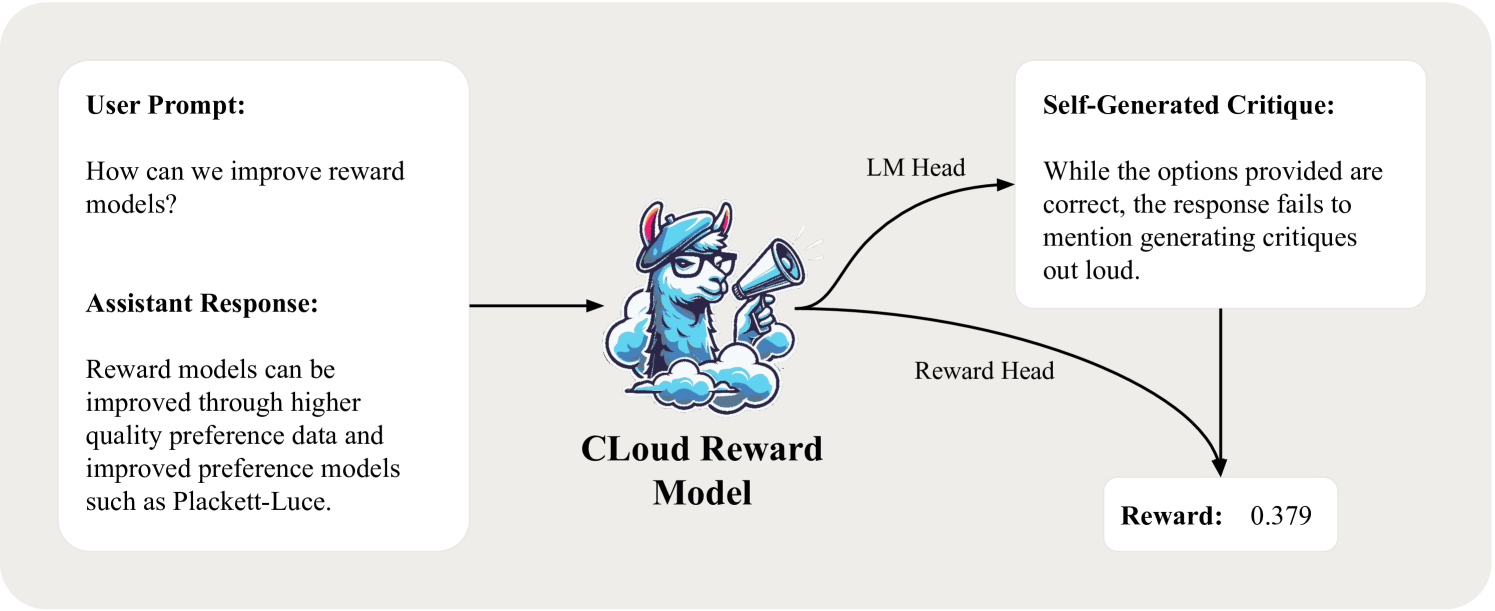
Overview of CLoud reward models compared to classic reward models and LLM-as-a-Judge.
Evaluation Highlights
- +4.65 (8B) and +5.84 (70B) percentage point improvement on RewardBench accuracy compared to classic reward models
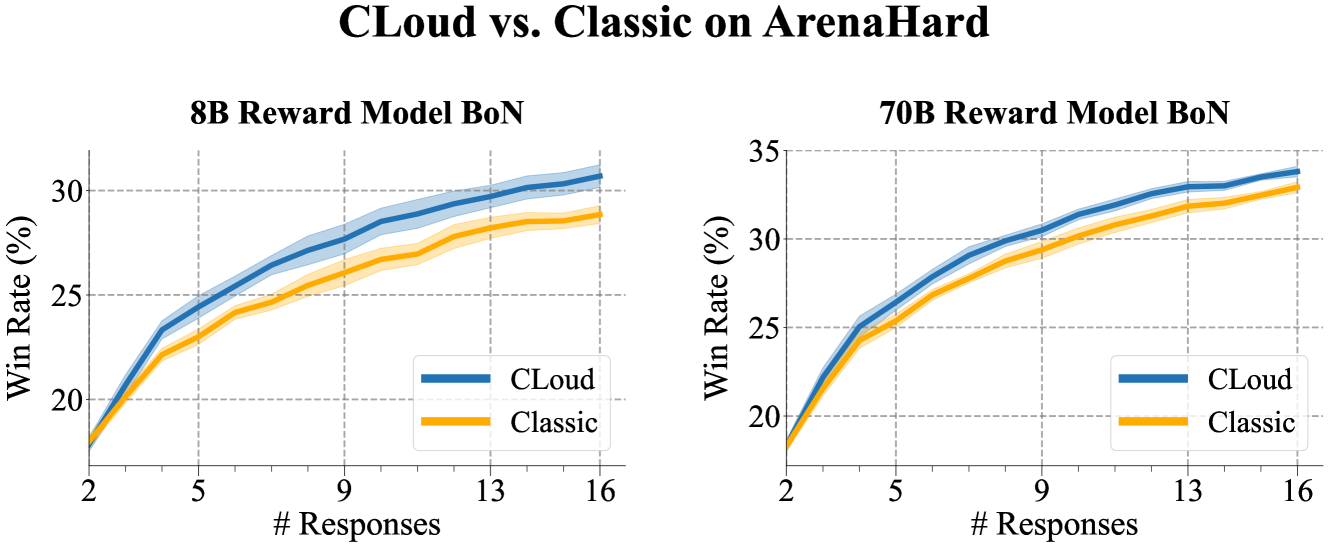
- Achieves Pareto improvement in win rates on ArenaHard when used as a Best-of-N scorer compared to standard reward models
- Self-consistency (marginalizing over multiple sampled critiques) further improves RewardBench accuracy by up to 0.70% for 8B models on reasoning tasks
Breakthrough Assessment
8/10
Strong empirical results showing that adding reasoning traces to reward models significantly boosts performance. Effectively bridges the gap between efficient scalar reward models and interpretable judge models.