📝 Paper Summary
Reward Modeling
Reinforcement Learning from Human Feedback (RLHF)
Reasoning Language Models
BR-RM improves reward modeling by forcing the judge to first select critical evaluation dimensions and then perform a targeted second-pass analysis, reducing the dilution of attention common in single-pass models.
Core Problem
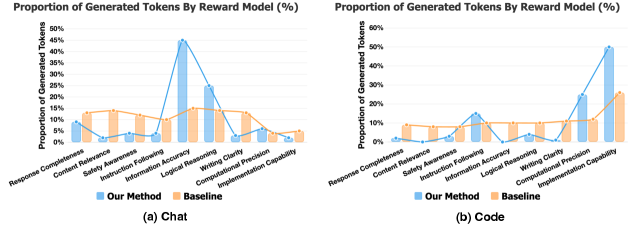
Standard scalar Reward Models (RMs) suffer from 'judgment diffusion': by trying to evaluate all quality criteria in a single pass, they spread attention too thin and fail to catch subtle errors.
Why it matters:
- Current judges often miss quiet factual slips or local logic bugs because they lack the depth of focus needed for complex reasoning tasks
- Existing generative RMs typically collapse critiques into a single global decision without instance-adaptive focus, retaining the 'all-at-once' pressure of scalar models
Concrete Example:
When a Reasoning RM evaluates a complex response, it often allocates tokens evenly across all criteria (e.g., style, safety, correctness). Consequently, it might miss a subtle hallucination in a math derivation because it didn't dedicate specific compute to verifying that single step, resulting in 'shallow analysis'.
Key Novelty
Branch-and-Rethink Reward Model (BR-RM)
- Transfers the 'think twice' principle from solvers to judges: instead of one holistic score, the model executes a two-turn generative trace
- Turn 1 (Adaptive Branching) identifies specific risks (e.g., 'Check Factuality'); Turn 2 (Rethinking) executes a deep-dive analysis conditioned solely on those flagged risks
Architecture
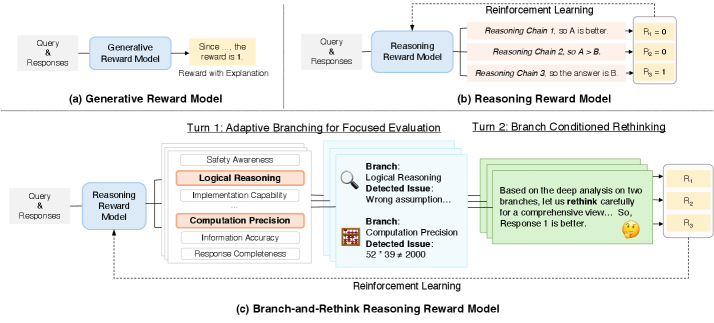
Comparison of Scalar RM, Generative RM, and the proposed Branch-and-Rethink (BR-RM) frameworks.
Evaluation Highlights
- Achieves 85.9 accuracy on RM-Bench with Qwen-14B, setting a new state-of-the-art and outperforming DeepSeek-V3-based judges
- BR-RM-Qwen-8B outperforms significantly larger baselines, including GPT-4o and Llama-3.1-70B-Instruct, on the RMB benchmark (70.1 vs 65.6 for GPT-4o)
- Ranks top-2 on RMB (74.7 with 14B model), demonstrating superior consistency across reasoning, knowledge, and safety domains compared to scalar RMs
Breakthrough Assessment
8/10
Significantly advances reward modeling by successfully operationalizing 'system 2' thinking for judges. The structured two-turn approach effectively solves the attention-dilution problem in scalar RMs.