📝 Paper Summary
Curriculum Learning
Reward Shaping
Inspired by toddler development, this paper proposes a Sparse-to-Dense (S2D) reward curriculum that starts with free exploration and transitions to potential-based dense rewards, improving generalization and smoothing the policy loss landscape.
Core Problem
Static reward densities fail to balance exploration and exploitation effectively: sparse rewards slow down learning, while dense rewards often bias agents toward suboptimal local minima.
Why it matters:
- Complex environments with high-dimensional inputs (e.g., egocentric 3D observations) require extensive exploration that dense rewards discourage.
- Existing methods relying solely on one reward type or Dense-to-Sparse transitions struggle to maintain optimal strategies or achieve robustness.
- Rugged policy loss landscapes in deep RL make optimization volatile and challenging, hindering generalization.
Concrete Example:
In a maze, an agent with only dense rewards might get stuck trying to walk through a wall toward the goal (short-term gain), while an agent with only sparse rewards might wander aimlessly without ever finding the goal due to lack of feedback.
Key Novelty
Toddler-Inspired Sparse-to-Dense (S2D) Reward Transition
- mimics human toddlers who transition from 'innate explorers' (engaging with environments without immediate rewards) to goal-directed learners guided by denser feedback
- Uses Potential-Based Reward Shaping (PBRS) to densify rewards during the transition while theoretically preserving the optimal policy
- Reverses the conventional 'easy-to-hard' or 'dense-to-sparse' intuition by prioritizing early free exploration to build robust cognitive maps before optimization
Architecture
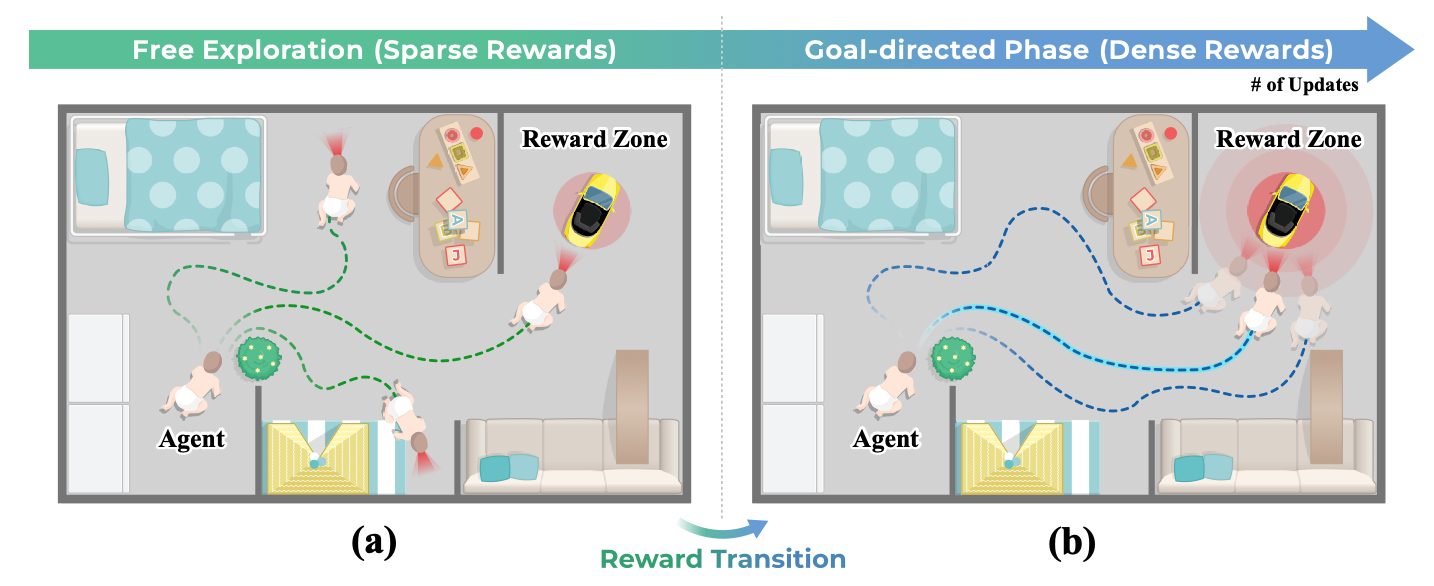
Conceptual illustration of the Toddler-inspired Reward Transition
Breakthrough Assessment
7/10
Offers a counter-intuitive but biologically grounded approach (Sparse-to-Dense) that addresses the specific problem of loss landscape smoothing in RL, though results in the provided text are qualitative.