📝 Paper Summary
Reward Model Evaluation
RLHF (Reinforcement Learning from Human Feedback)
Benchmarking
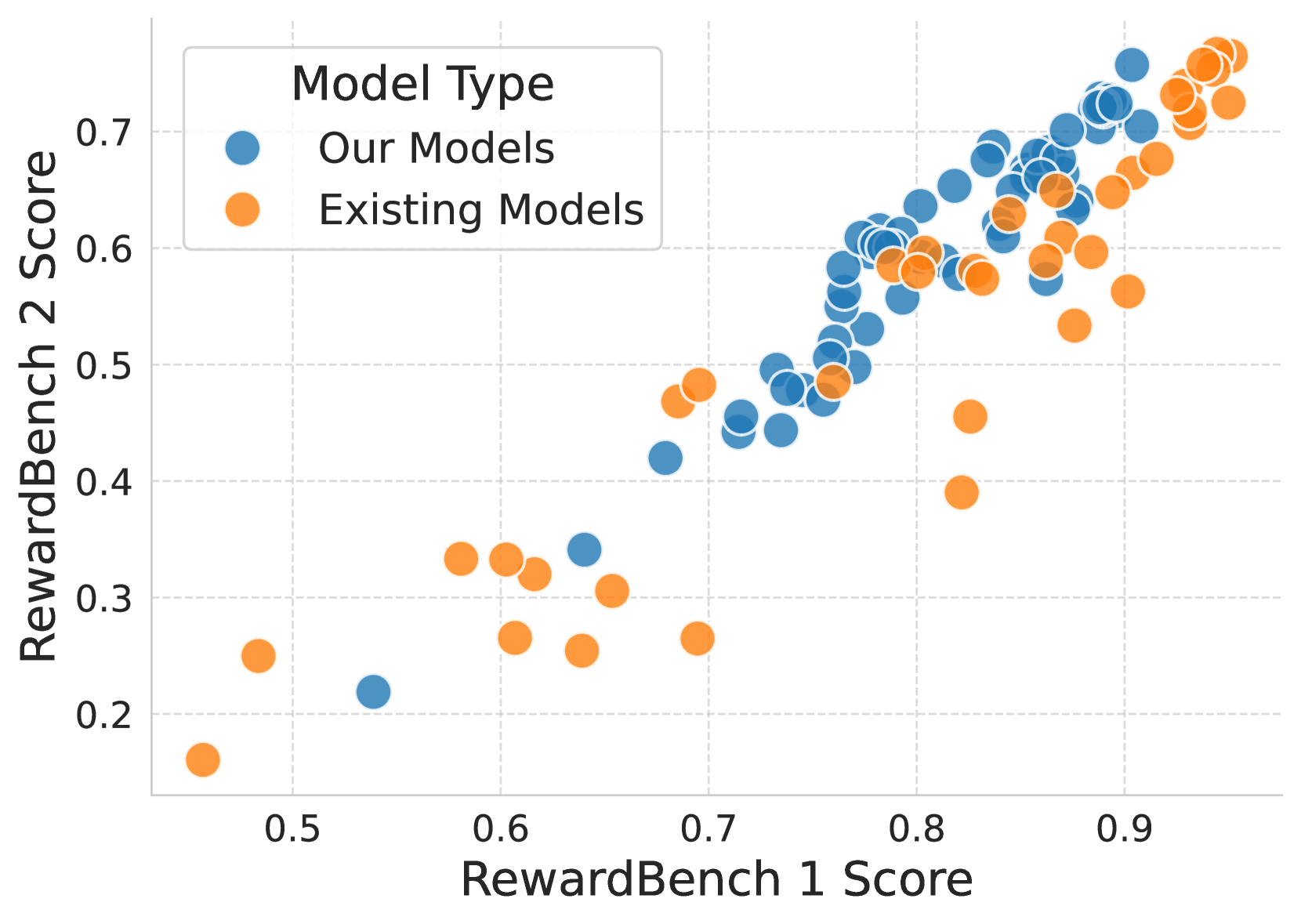
RewardBench2 introduces a challenging, multi-skill benchmark for reward models using unseen human prompts and 4-way comparison tasks, revealing significant performance drops in current models compared to previous benchmarks.
Core Problem
Existing reward model benchmarks often rely on reused prompts from downstream evaluations (leading to contamination) and fail to distinguish between strong models due to saturated performance on simple chosen/rejected pairs.
Why it matters:
- Progress in reward model evaluation lags behind reward model effectiveness, meaning high benchmark scores often don't translate to better downstream policy performance
- Users lack reliable signals to select the best reward model for specific post-training needs like RLHF or inference-time scaling
- Overfitting to easy or contaminated benchmarks creates a false sense of alignment progress
Concrete Example:
Current leading reward models score ~20 points lower on RewardBench2 than on the original RewardBench, exposing failures in domains like Math and Precise Instruction Following where accuracy drops below 70% and 40% respectively.
Key Novelty
Harder 4-way ranking on unseen prompts
- Shifts from binary classification (1 chosen vs. 1 rejected) to a 4-way task (1 chosen vs. 3 rejected), lowering the random baseline to 25% and increasing difficulty
- Sources ~70% of prompts from unseen human queries (WildChat) rather than recycling prompts from existing benchmarks to prevent contamination
- Introduces a 'Ties' domain to test if models can avoid arbitrary preferences between equally valid answers (e.g., 'red' vs. 'green' for 'Name a color of the rainbow')
Architecture
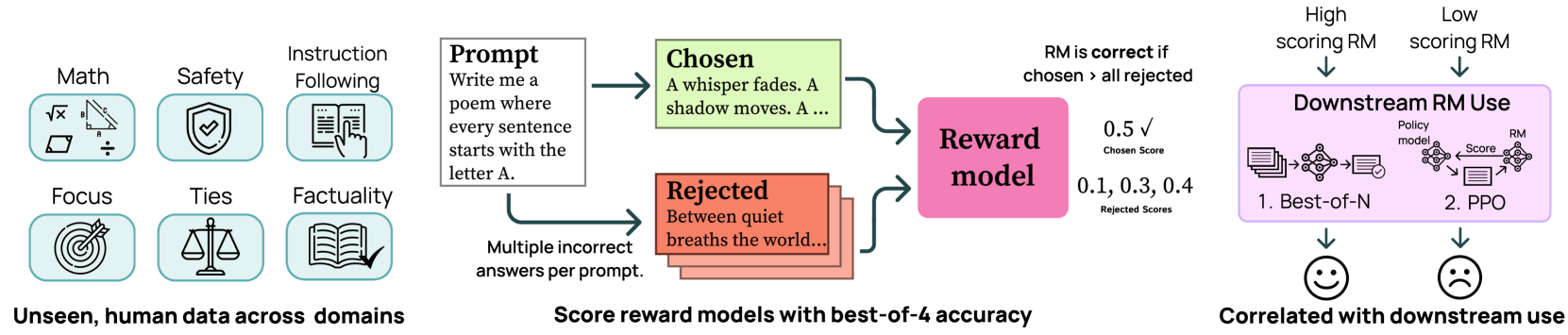
Conceptual diagram of the RewardBench2 evaluation pipeline and its application in downstream tasks.
Evaluation Highlights
- Leading reward models score ~20 points lower on average on RewardBench2 compared to RewardBench v1, indicating increased difficulty
- In the Precise Instruction Following subset, leading models achieve below 40% accuracy (where random baseline is 25%)
- Training reward models for 2 epochs (vs. standard 1 epoch) improves performance for 8 of the top 18 models evaluated
Breakthrough Assessment
8/10
Significantly raises the bar for RM evaluation by fixing contamination and saturation issues. The shift to 1-vs-3 ranking and inclusion of 'Ties' are methodologically strong updates that better reflect downstream needs.