📝 Paper Summary
Code Generation
Reward Modeling / Verification
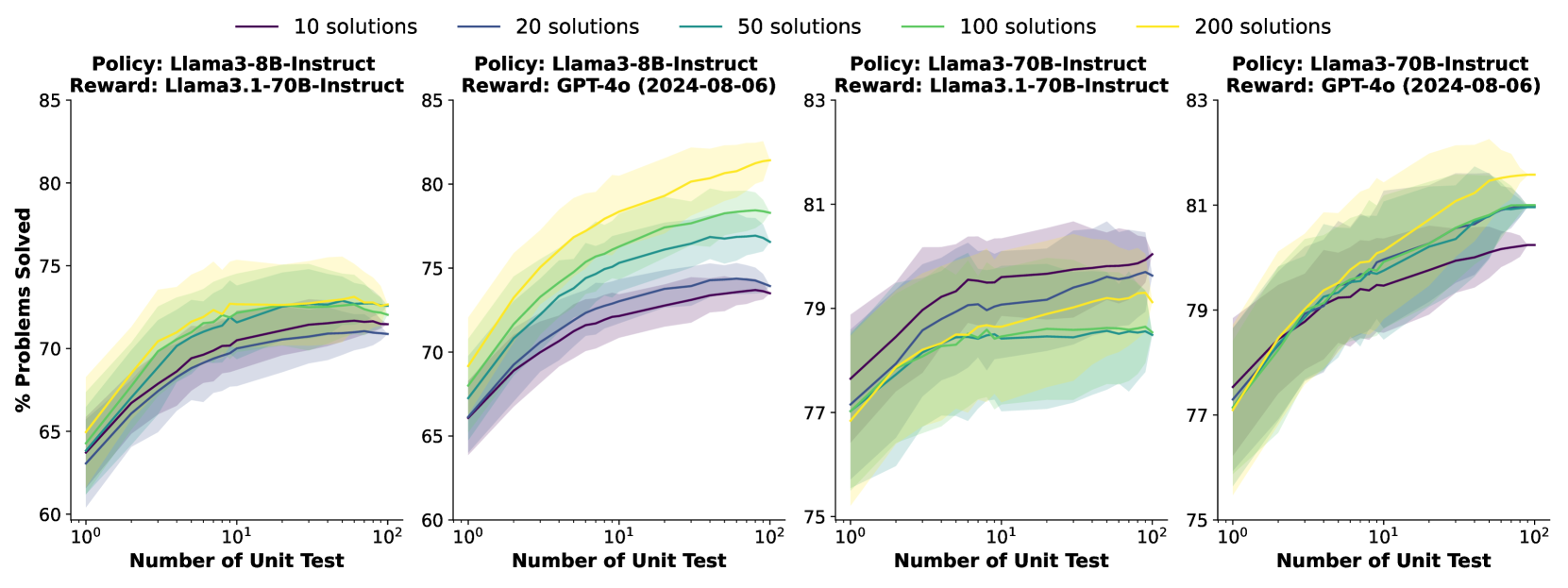
CodeRM-8B enhances code generation by scaling the number of LLM-generated unit tests to verify candidate solutions, dynamically allocating more test-time compute to harder problems.
Core Problem
LLMs often generate incorrect code with high confidence, and existing unit test-based verifiers are unreliable because the generated tests themselves may be flawed.
Why it matters:
- Generating correct code on the first attempt is difficult due to complex reasoning requirements
- While generating multiple candidate solutions (Best-of-N) helps, identifying the correct one remains a challenge if the verifier (reward signal) is noisy
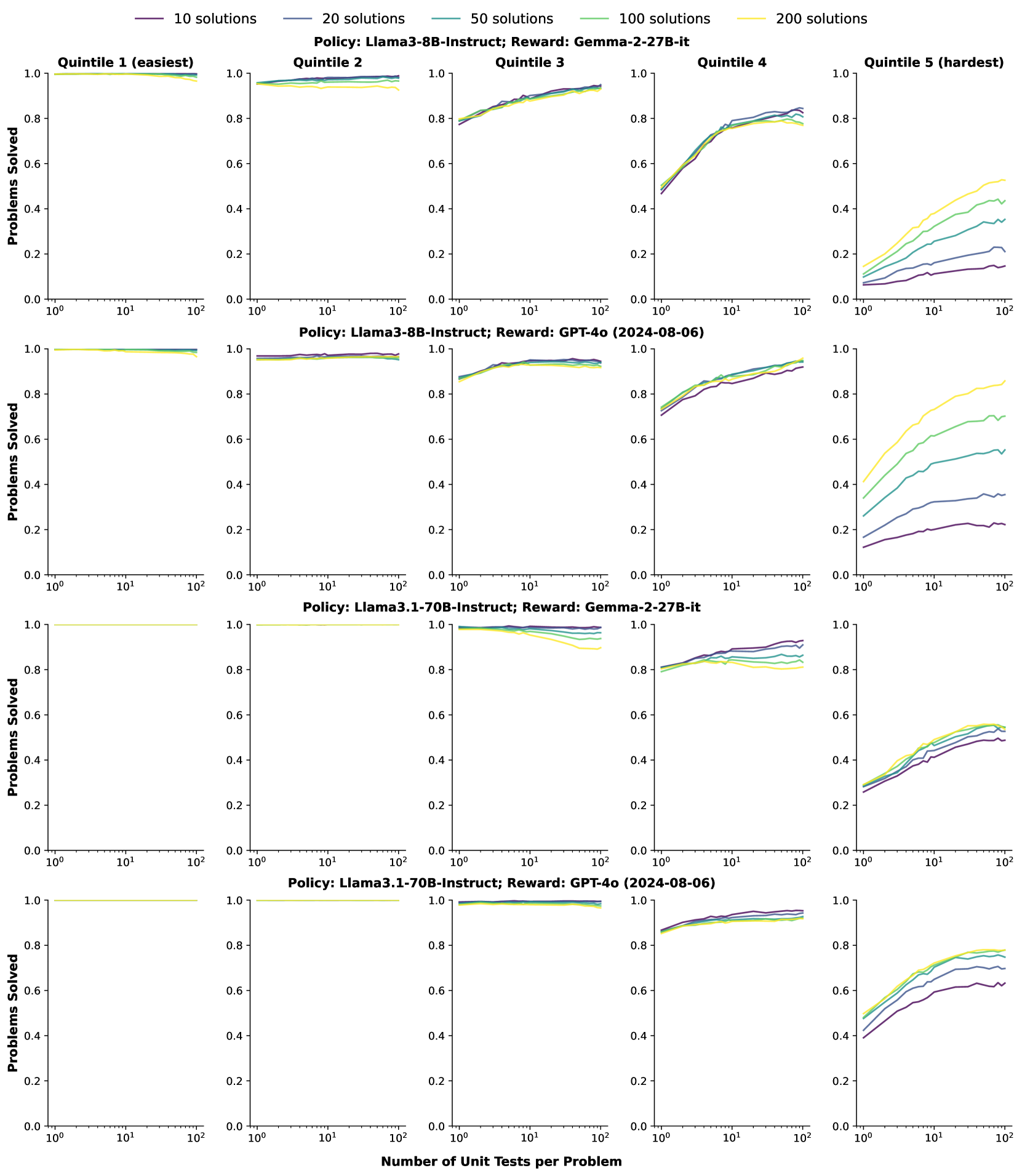
- Standard approaches use a fixed budget of unit tests, which is inefficient: easy problems waste compute, while hard problems don't get enough verification
Concrete Example:
For a complex algorithmic problem, an LLM might generate a solution that looks plausible but fails edge cases. If the verifier only generates 2 simple unit tests, the buggy solution might pass both (false positive). Scaling to 100 tests increases the chance of catching the bug.
Key Novelty
Dynamic Scaling of Unit Test Verification (CodeRM)
- Pioneering observation that scaling the number of generated unit tests (test-time compute) positively correlates with reward signal quality, especially for harder problems
- Develops CodeRM-8B, a specialized model fine-tuned on high-quality synthetic data to generate robust unit tests
- Implements a dynamic scaling mechanism that estimates problem difficulty using a lightweight probe and allocates more unit test generation budget to harder problems
Architecture
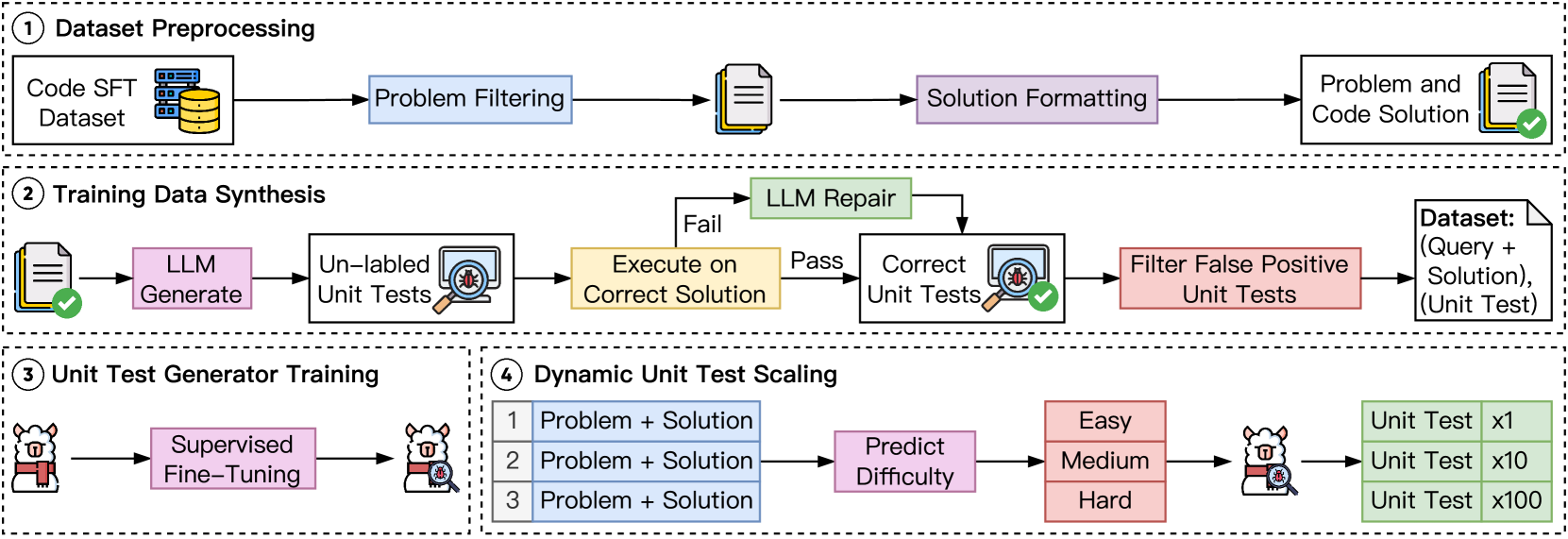
The overall pipeline for CodeRM construction and deployment. It shows four stages: Dataset Preprocessing, Unit Test Generation (synthesis pipeline), Model Training (SFT), and Dynamic Inference.
Evaluation Highlights
- +18.43% pass rate improvement on HumanEval Plus for Llama3-8B using CodeRM-8B compared to baseline
- +3.42% improvement for GPT-4o-mini on HumanEval Plus, showing benefits even for strong proprietary models
- Dynamic scaling achieves up to ~0.5% gain on MBPP Plus over static scaling at fixed computational cost
Breakthrough Assessment
8/10
Strong empirical evidence for 'test-time training' principles applied to verifiers. The dynamic allocation strategy is a smart efficiency optimization. Significant gains on major benchmarks.