📝 Paper Summary
Inference-time scaling
Reasoning strategies
The paper surveys inference-time scaling strategies, organizing them into output-focused methods (reasoning, search, decoding) and input-focused methods (RAG, few-shot) that improve LLM performance via additional compute without retraining.
Core Problem
Scaling model size and training data (pre-training scaling) faces diminishing returns due to data scarcity and high costs, creating a need for alternative performance improvement methods.
Why it matters:
- High-quality training data is becoming a fundamental bottleneck
- Retraining massive models is resource-intensive and often unsustainable
- Inference-time strategies allow models to adapt and reason better on complex tasks using existing parameters
Concrete Example:
In simple tasks, a model might answer directly. In complex math problems, direct answering fails; however, using Chain-of-Thought (CoT) consumes more inference tokens (FLOPs) to generate intermediate steps, leading to the correct answer.
Key Novelty
Unified Framework for Inference-Time Scaling
- classifies techniques into 'Output-focused' (generating more tokens/paths like CoT, MCTS) and 'Input-focused' (processing more tokens like RAG, few-shot)
- Redefines RAG and few-shot learning as scaling methods because they proportionally increase inference FLOPs through longer prompt contexts to enhance performance
Architecture
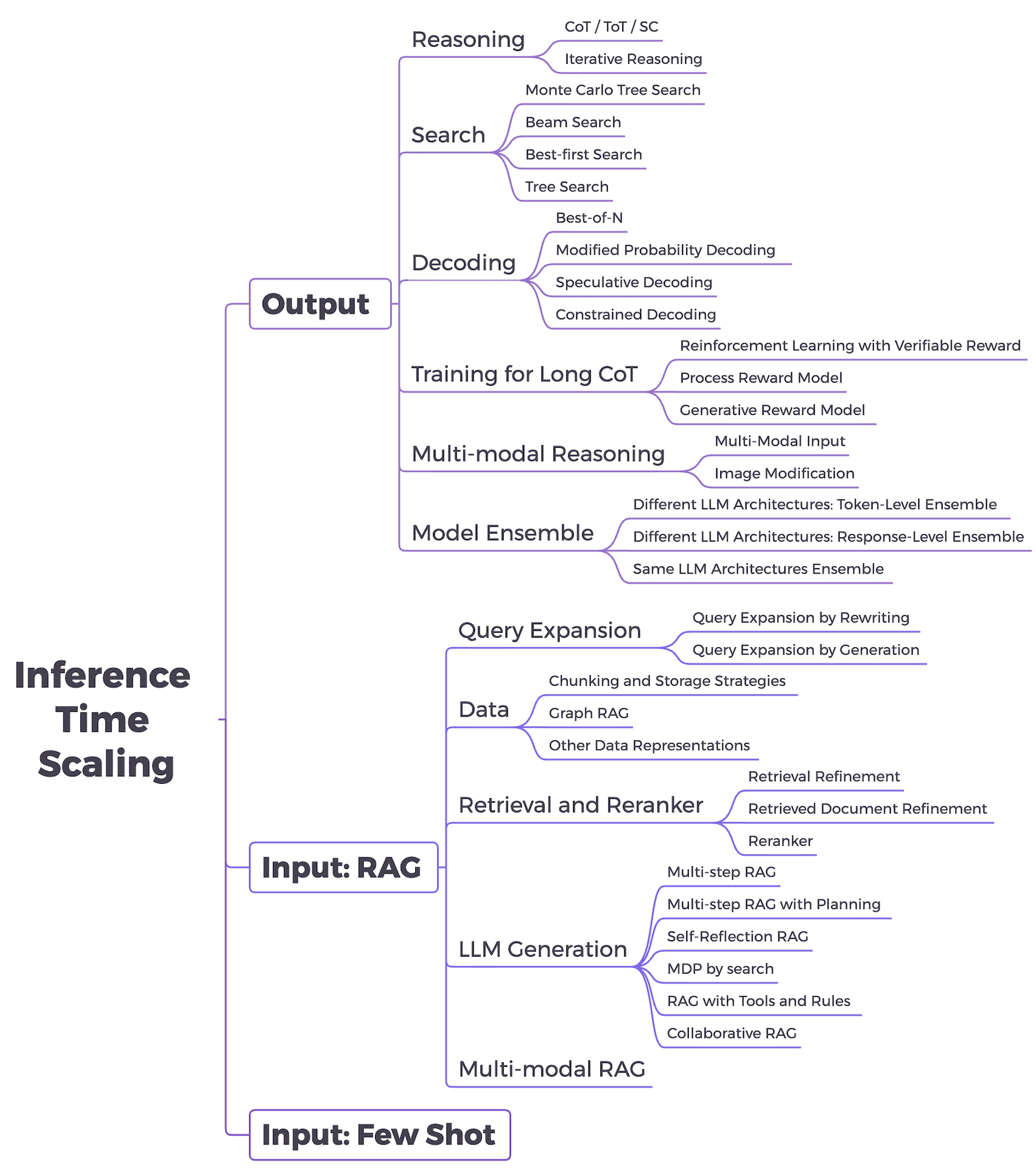
A taxonomy diagram of inference-time scaling strategies, dividing them into Input-focused and Output-focused categories.
Evaluation Highlights
- Review paper: No novel experimental results reported
- Synthesizes roughly 50+ existing methods (e.g., CoT, ToT, MCTS, RAG) into a single taxonomy
- Highlights that methods like Best-of-N and MCTS trade increased inference cost for higher accuracy
Breakthrough Assessment
4/10
This is a survey paper, not a new method. It provides a useful taxonomy for understanding the shift from pre-training scaling to inference scaling but introduces no new algorithms or results.