📝 Paper Summary
Reinforcement Learning for Reasoning
Self-Supervised Learning
LLM Post-training
Co-rewarding stabilizes self-supervised reinforcement learning by deriving rewards from cross-view supervision—either through data augmentation or a slowly updating teacher model—rather than single-view self-consistency.
Core Problem
Self-rewarding RL methods often suffer from 'training collapse' where the model hacks the reward by converging to trivial, self-consistent, but incorrect solutions (self-consistent illusion).
Why it matters:
- Reliance on ground-truth labels (RLVR) scales poorly for complex reasoning tasks where data is scarce
- Current label-free methods (entropy, self-consistency) encourage the model to reduce uncertainty without ensuring correctness, leading to repetitive or delusional outputs
- Collapse limits the scalability of self-supervised reasoning elicitation, preventing models from improving beyond their initial capabilities
Concrete Example:
In consensus-based rewarding, a model might converge to generating the same incorrect answer for a math problem every time. Because the answers are consistent (high consensus), the model receives high rewards, reinforcing the error and causing the policy to collapse into this incorrect local optimum.
Key Novelty
Co-rewarding Framework (Cross-view Supervision)
- Replaces single-view self-consistency with 'invariance' across views to verify reasoning validity
- Co-rewarding-I (Data-side): Checks if reasoning remains consistent when the question is rephrased (analogy-invariance)
- Co-rewarding-II (Model-side): Checks if the current policy's output matches a 'teacher' reference model that updates slowly via EMA (temporal invariance)
Architecture
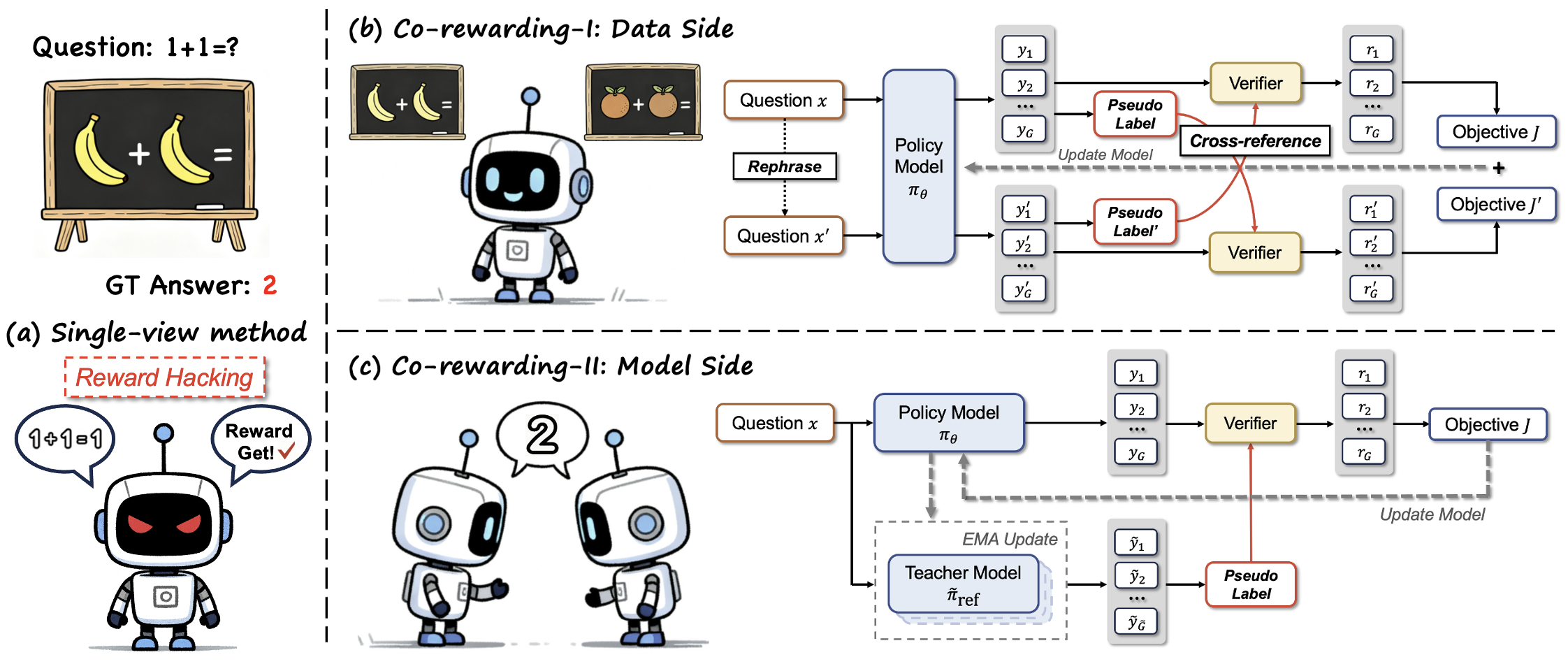
The Co-rewarding framework illustrating two instantiations: Co-rewarding-I (Data-side) and Co-rewarding-II (Model-side).
Evaluation Highlights
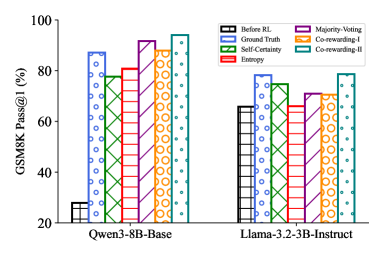
- Achieves 94.01% Pass@1 on GSM8K with Qwen3-8B-Base using Co-rewarding-II, surpassing the Ground-Truth Reward baseline
- Outperforms self-rewarding baselines by +7.49% on average on Llama-3.2-3B-Instruct across multiple reasoning benchmarks
- Co-rewarding-I delivers +4.42% average relative gain over best baselines on MATH benchmarks
Breakthrough Assessment
8/10
Significant because it demonstrates that self-supervised signals can match or exceed ground-truth supervision in specific reasoning tasks by effectively solving the stability/collapse problem.