📝 Paper Summary
Interpretability of Chain-of-Thought
Mathematical Reasoning Analysis
Cognitive Architectures for LLMs
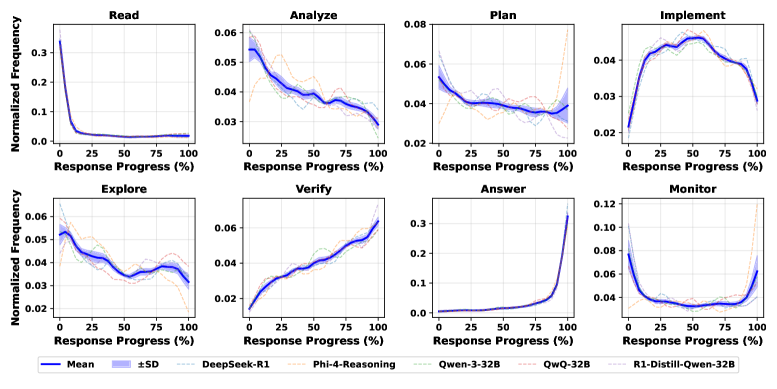
ThinkARM applies Schoenfeld's Episode Theory to automatically segment LLM reasoning traces into functional stages like Explore and Verify, revealing that reasoning models uniquely exhibit iterative exploration-verification loops compared to standard models.
Core Problem
Current evaluations of reasoning models rely on outcome-oriented metrics (accuracy, length) or token-level statistics, which fail to capture the functional structure and intermediate dynamics of how models actually think.
Why it matters:
- Longer reasoning chains ('overthinking') do not always equal better correctness, yet we lack tools to diagnose why specific long traces fail
- Functional behaviors like 'exploration' vs 'execution' are discussed intuitively but lack rigorous quantification, making it hard to compare reasoning styles across models
- Understanding the internal structure of reasoning is crucial for diagnosing failures and distinguishing genuine reasoning from mere pattern matching or memorization
Concrete Example:
When solving a math problem, a standard model might jump straight to 'Implement' (calculating values). A reasoning model might first 'Analyze' the problem structure, then 'Explore' a hypothesis, then 'Verify' it. Current metrics only see that the second model generated more tokens, missing the structural difference in cognitive control.
Key Novelty
ThinkARM (Anatomy of Reasoning in Models)
- Adapts Schoenfeld's cognitive science framework (originally for human problem solving) to abstract LLM token sequences into eight functional episodes (e.g., Read, Analyze, Explore, Implement, Verify)
- Uses a strong LLM as an automated annotator to label sentences in reasoning traces at scale, enabling quantitative analysis of 'cognitive heartbeats' across different model families
Architecture

Overview of the ThinkARM framework, illustrating the mapping from raw reasoning tokens to functional episode labels
Evaluation Highlights
- Reasoning models (e.g., DeepSeek-R1) allocate significantly more budget to 'Analyze' and 'Explore' episodes compared to non-reasoning models which are dominated by 'Implement'
- Correct solutions are strongly associated with 'Explore → Monitor' and 'Explore → Analyze' transitions, while incorrect solutions often show 'Explore' leading directly to 'Verify' or premature termination
- Distilled reasoning models (e.g., R1-Distill-Qwen-1.5B) preserve the episode allocation structure of their teacher models despite being much smaller
Breakthrough Assessment
8/10
Provides a novel, theory-grounded lens for analyzing CoT that moves beyond token length. The findings on 'cognitive heartbeats' and the distinct structural signatures of reasoning models are empirically strong and insightful.