📝 Paper Summary
LLM Post-training
Reinforcement Learning for Reasoning
VCRL dynamically selects training samples with high reward variance—indicating they are at the edge of the model's current ability—and replays them via a memory bank to improve RL efficiency.
Core Problem
Existing rollout-based RL methods (like GRPO) sample training queries randomly, ignoring that samples too easy or too hard for the current model state provide little learning signal (low gradient variance).
Why it matters:
- Inefficient training: Models waste compute on samples they already mastered (reward always 1) or cannot yet solve (reward always 0).
- Dynamic difficulty: A sample's difficulty changes as the model learns, making static curriculum sorting (e.g., by question length) ineffective.
- Human learning analogy: Humans learn best when tasks gradually increase in difficulty, matching their current zone of proximal development, which standard RL sampling fails to mimic.
Concrete Example:
If a math problem is too hard, the model gets 0 reward across all rollouts (variance ≈ 0). If too easy, it gets 1 reward everywhere (variance ≈ 0). VCRL identifies valuable samples where the model succeeds ~50% of the time (high variance) and prioritizes them.
Key Novelty
Variance-based Curriculum Reinforcement Learning (VCRL)
- Uses the variance of rewards within a group of rollouts as a proxy for sample difficulty; high variance implies the model is uncertain and the sample is 'learning-rich'.
- Maintains a 'high-value memory bank' of these high-variance samples to replay them during training, ensuring the model focuses on the frontier of its capabilities rather than random data.
Architecture
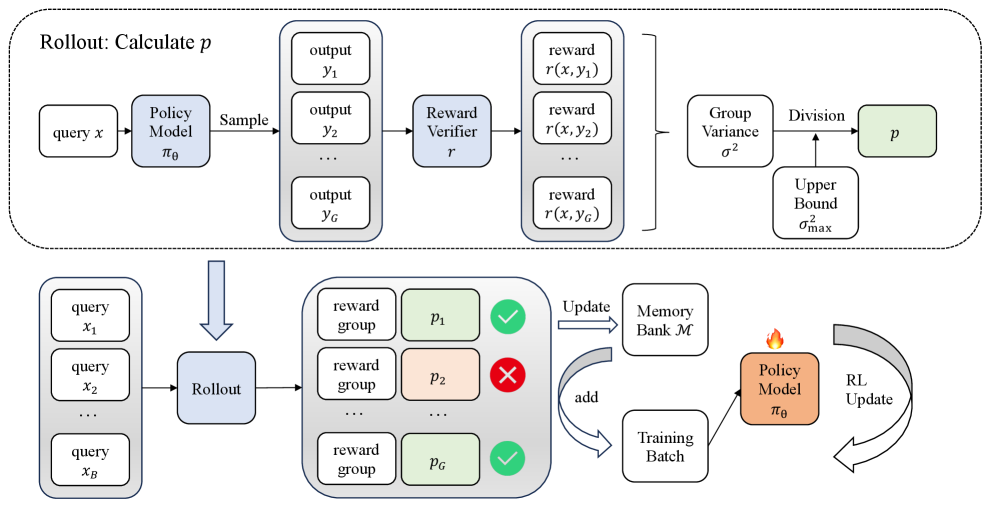
The overall VCRL framework flow. It illustrates how a batch of queries generates responses, how variance is calculated to filter samples, and how the memory bank interacts with the training batch.
Evaluation Highlights
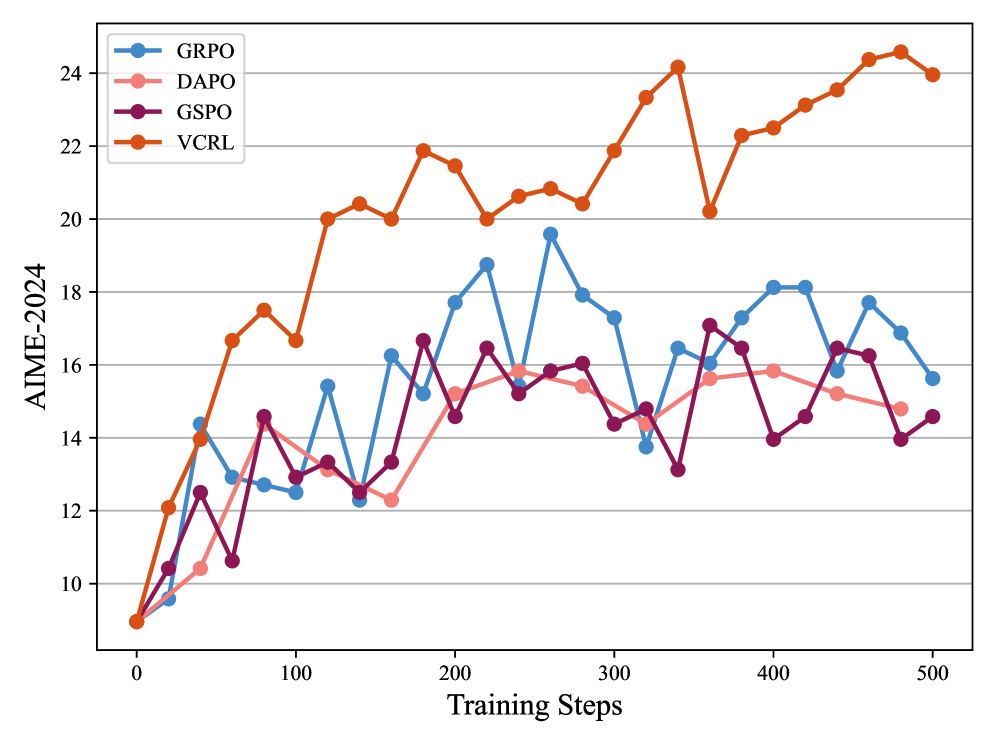
- +24.8 points average improvement on Qwen3-8B-Base across 5 math benchmarks compared to the base model, significantly outperforming standard RL.
- +4.67 points average improvement over the strongest baseline (GSPO) on Qwen3-8B-Base (57.76 vs 53.09).
- Achieves SOTA performance on challenging competition math datasets like AIME-2024 and AIME-2025 across both 4B and 8B model sizes.
Breakthrough Assessment
7/10
Strong empirical gains on difficult math benchmarks and a theoretically grounded (variance-reduction) motivation. The method is a smart integration of curriculum learning into GRPO rather than a fundamental architectural shift.