📊 Experiments & Results
Evaluation Setup
Reward Model evaluation on standard benchmarks and LLM alignment evaluation
Benchmarks:
- RM-Bench (Reward Model Evaluation)
- JudgeBench (Reward Model Evaluation)
- PrincipleBench (Principle Adherence) [New]
- MT-Bench (General Chat Capability)
- WildBench (Real-world User Prompts)
- Arena Hard v2 (Hard Prompts)
Metrics:
- Accuracy (for Reward Models)
- Alignment Performance (Win rates / Scores on chat benchmarks)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| JudgeBench | Accuracy | Not reported in the paper | 81.4 | Not reported in the paper |
| RM-Bench | Accuracy | Not reported in the paper | 86.2 | Not reported in the paper |
Experiment Figures
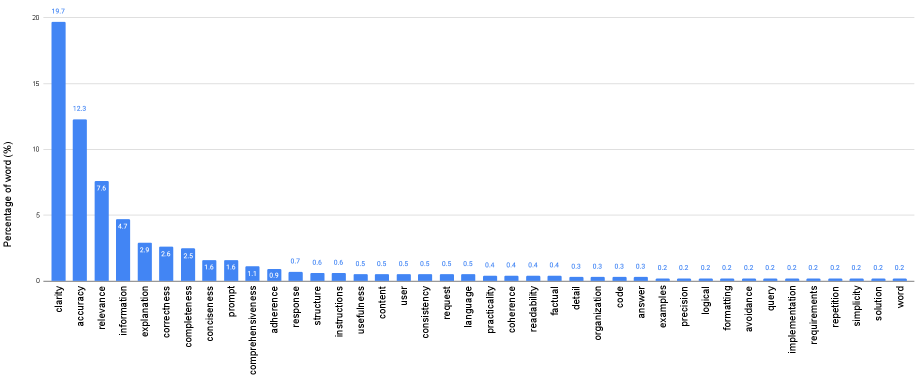
Word cloud/Frequency distribution of the 1,414 unique extracted principles
Main Takeaways
- RLBFF bridges the gap between the versatility of RLHF and the precision of RLVR.
- Models trained with RLBFF achieve top-tier performance on reward modeling benchmarks (JudgeBench, RM-Bench).
- Alignment using RLBFF allows open-weights models (Qwen3-32B) to match or exceed much larger proprietary models (o3-mini, DeepSeek R1) on general benchmarks.
- The method is highly efficient, achieving these results at <5% of the inference cost of the proprietary models compared.