📝 Paper Summary
Image Captioning
Reinforcement Learning with Verifiable Rewards (RLVR)
Vision-Language Pretraining
CapRL trains an image captioner using reinforcement learning where the reward is the ability of a blind LLM to answer questions about the image solely based on the generated caption.
Core Problem
Supervised Fine-Tuning (SFT) for image captioning relies on expensive, non-scalable human data and causes models to memorize specific ground-truth phrasing rather than learning to generate diverse, dense descriptions.
Why it matters:
- SFT models struggle to generate the wide variety of valid descriptions possible for a single image, limiting their generality.
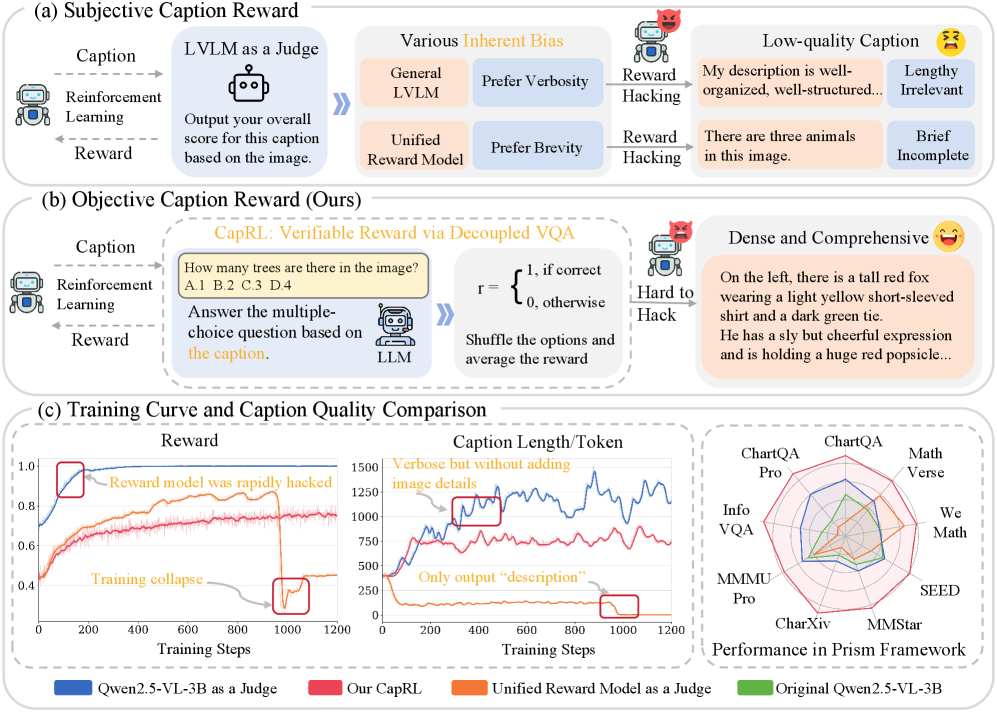
- Existing RL approaches use subjective rewards (like LLM-as-a-judge) that are prone to reward hacking (e.g., maximizing verbosity) or require expensive reference-based metrics that fail on long captions.
- Dense, accurate captions are critical for pre-training Large Vision-Language Models (LVLMs) to align visual and linguistic domains effectively.
Concrete Example:
A captioning model trained with SFT might output a short, memorized phrase like 'a dog on grass' for a complex scene. In contrast, CapRL forces the model to include details like 'red frisbee' because a verifier asks 'What color is the frisbee?', and the caption must contain the answer for the blind LLM to get it right.
Key Novelty
Captioning Reinforcement Learning (CapRL) with Perception-Reasoning Decoupled Reward
- Defines caption quality by utility: a good caption contains enough information for a text-only LLM (blind to the image) to correctly answer visual questions about that image.
- Uses a two-stage pipeline: (1) LVLM generates a caption, (2) Blind LLM answers multiple-choice questions using only that caption. The answer accuracy serves as the objective, verifiable reward for RL training.
Architecture
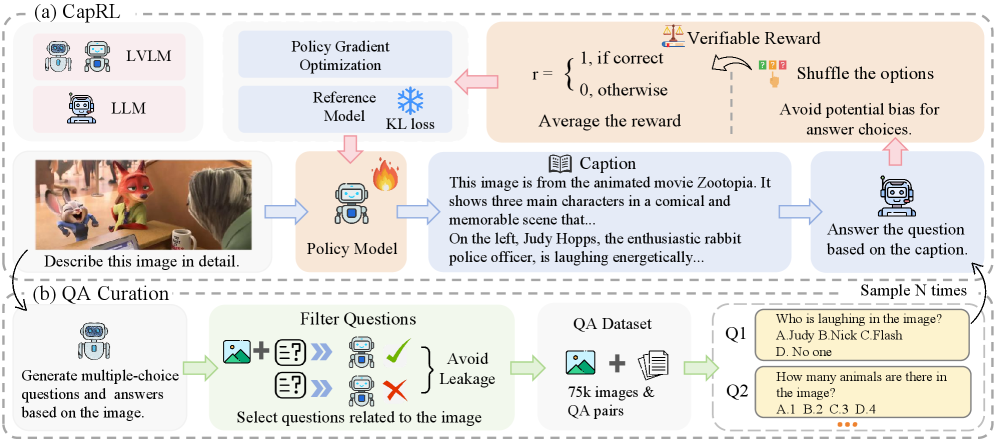
The CapRL training pipeline, illustrating the two-stage decoupled reward mechanism.
Evaluation Highlights
- +6.8% accuracy improvement on InfoVQA and +3.6% on ChartVQA when pretraining with CapRL-1M compared to DenseFusion-1M.
- Outperforms the ShareGPT4V-1M baseline by 1.6% on MMStar and 1.8% on MMBench, showing benefits for natural images.
- Achieves caption quality comparable to the much larger Qwen2.5-VL-72B model within the Prism evaluation framework, exceeding the baseline by an average margin of 8.4%.
Breakthrough Assessment
8/10
Successfully applies RLVR to a subjective task by converting it into an objective proxy task (VQA utility). The resulting dataset (CapRL-5M) yields significant gains in downstream LVLM pretraining.