📝 Paper Summary
Video Temporal Grounding (VTG)
Multimodal Large Language Models (MLLMs)
TimeLens establishes a reliable baseline for video temporal grounding by rigorously cleaning defective benchmarks and applying thinking-free reinforcement learning on high-quality re-annotated data.
Core Problem
Existing video temporal grounding benchmarks are rife with low-quality queries (ambiguous, non-unique) and inaccurate timestamps, causing misleading evaluations where models learn shortcuts rather than temporal perception.
Why it matters:
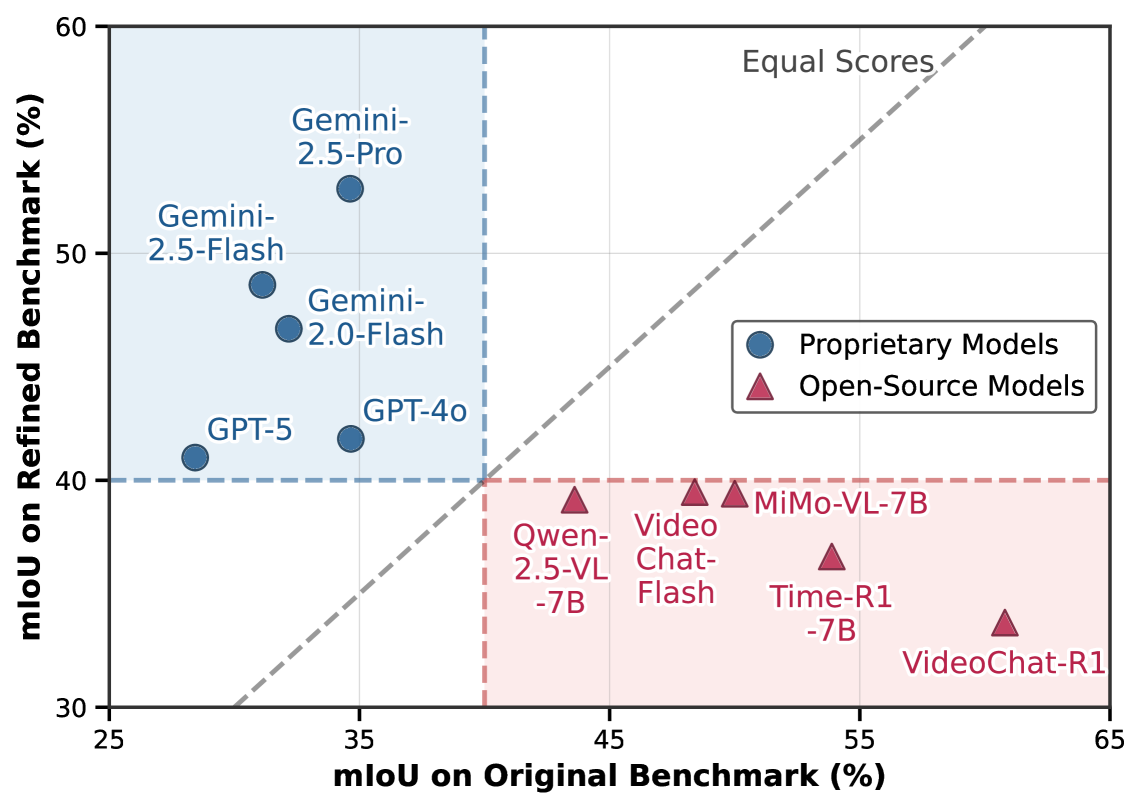
- Current benchmarks misguide research: open-source models often 'win' on legacy leaderboards by exploiting dataset biases, while robust proprietary models rank poorly, a trend that reverses on clean data
- Without accurate temporal grounding, MLLMs cannot reliably answer 'when' events happen, limiting their utility in fine-grained video understanding and reasoning systems
Concrete Example:
In Charades-STA, multiple nearly identical queries often describe the same event, or queries like 'ending credits' leak temporal position. A model trained on this might output a correct timestamp based on text shortcuts without watching the video, failing when tested on unique, perception-dependent queries.
Key Novelty
TimeLens (Data Curation + RLVR Algorithm)
- Constructs 'TimeLens-Bench' by manually auditing and re-annotating popular benchmarks (Charades-STA, ActivityNet, QVHighlights) to enforce strict uniqueness and precision criteria
- Develops 'TimeLens-100K', a large-scale training set created via automated re-annotation of noisy corpora using advanced MLLMs
- Proposes a 'thinking-free' RLVR training recipe that optimizes directly for IoU (Intersection over Union) using interleaved textual timestamp encoding, avoiding complex architectural add-ons
Architecture
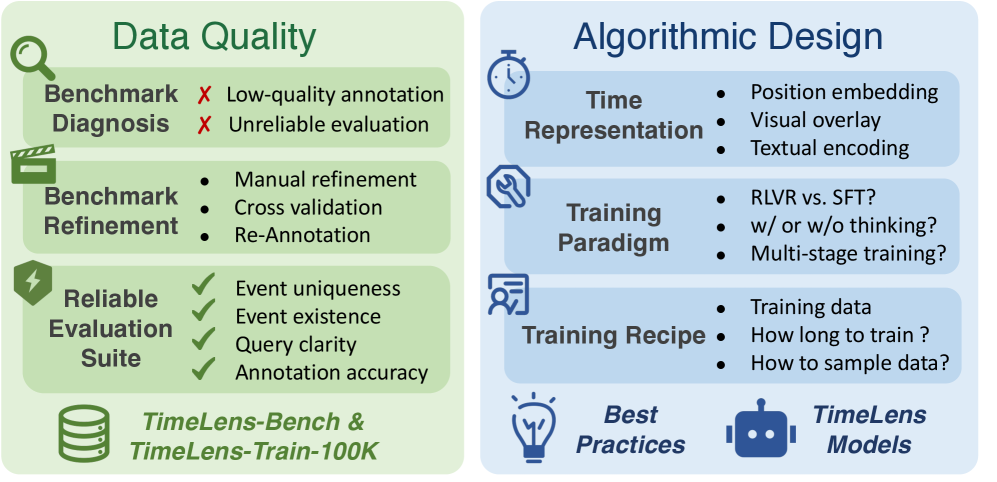
Conceptual framework for building TimeLens MLLMs, highlighting the dual focus on Data Quality and Algorithmic Design.
Evaluation Highlights
- Discovers 20.6% of samples in Charades-STA violate query uniqueness and 34.9% have annotation accuracy issues
- Reverses model rankings: Proprietary models (Gemini-1.5-Pro) significantly outperform open-source baselines on the refined TimeLens-Bench, whereas they lagged behind on legacy benchmarks
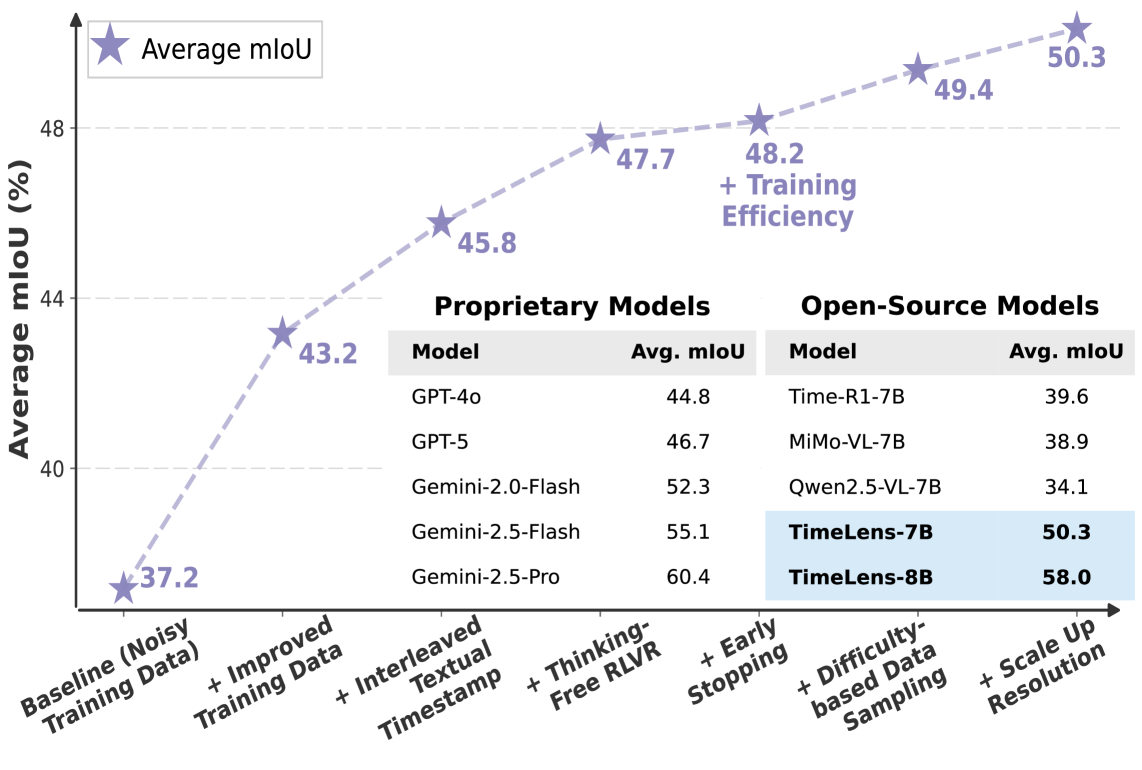
- TimeLens-8B (based on Qwen3-VL) achieves state-of-the-art performance on TimeLens-Bench, surpassing proprietary models like GPT-5 and Gemini-2.5-Flash
Breakthrough Assessment
8/10
Critically exposes severe flaws in standard benchmarks that have likely skewed the field. The proposed data pipeline and strong baseline (TimeLens) reset the standard for future VTG research.