📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Multimodal Reasoning
PAPO improves multimodal reasoning by adding a training objective that rewards the model when masking the visual input significantly changes its output, forcing reliance on visual cues.
Core Problem
Current RLVR methods for multimodal models focus only on final answer correctness, often allowing models to ignore visual inputs and rely on textual biases.
Why it matters:
- 67% of errors in multimodal reasoning stem from perception failures where the model misinterprets visual content despite having correct reasoning logic
- Existing RLVR objectives (like GRPO) tailored for text do not explicitly incentivize visual grounding
- Alternative solutions like reward modeling or separate captioning steps add significant computational overhead or rigid pipeline constraints
Concrete Example:
In a geometry problem (Figure 1), a standard RL-trained model correctly performs the algebraic steps but associates variable 'x' with the wrong side of the triangle because it fails to ground its reasoning in the image.
Key Novelty
Perception-Aware Policy Optimization (PAPO)
- Implicit Perception Loss: Maximizes the difference (KL divergence) between the model's policy given the full image and its policy given a masked/corrupted image, forcing the image to matter
- Double Entropy Loss: Regularizes the training by minimizing the entropy of both the original and masked policies to prevent the model from 'hacking' the divergence loss with high-entropy garbage
Architecture
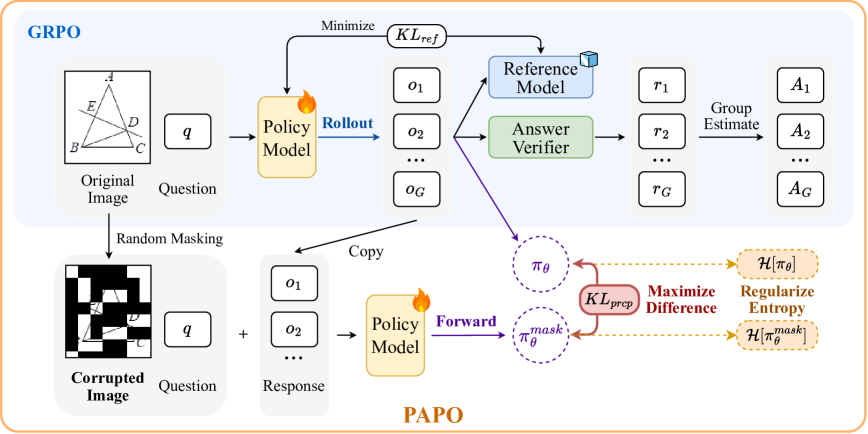
Overview of the PAPO algorithm integrated into the RLVR framework. It illustrates how the policy interacts with both original and masked visual inputs.
Evaluation Highlights
- Achieves average improvements of 4.4%-17.5% over GRPO and DAPO baselines across eight multimodal benchmarks
- Gains are highest (8.0%-19.1%) on vision-dependent tasks like LogicVista and MathVerseV where visual clues are essential
- Reduces perception-related errors by 30.5% compared to standard GRPO training, confirming improved visual grounding
Breakthrough Assessment
8/10
Simple yet highly effective drop-in replacement for standard RLVR algorithms that addresses the specific 'blindness' of multimodal RL. Significant error reduction with no extra data.
