📝 Paper Summary
LLM Reasoning
Mechanistic Interpretability
Steerability/Control
Self-reflection is a latent capability already present in pretrained models (not just RLVR fine-tuned ones) and can be activated or controlled by manipulating a specific direction in the model's hidden state space.
Core Problem
While self-reflection (revisiting and correcting reasoning) improves LLM performance, its origins are unclear—is it an emergent property of RLVR or pretraining?—and its verbosity increases inference costs.
Why it matters:
- Understanding whether reflection is innate or learned is crucial for the foundations of reasoning in LLMs
- Reflection often triggers 'wait' tokens that increase accuracy but slow down inference and increase costs
- Current methods lack fine-grained control to balance the trade-off between reasoning quality (accuracy) and computational efficiency (length)
Concrete Example:
A standard pretrained model (e.g., Qwen2.5) rarely self-reflects (0.6% rate) and may answer incorrectly. However, when probed with a specific reasoning trace, it can correct itself. Conversely, fine-tuned reasoning models reflect excessively (almost 100%), wasting compute on simple problems.
Key Novelty
Reflection-Inducing Probing & Self-Reflection Vector Steering
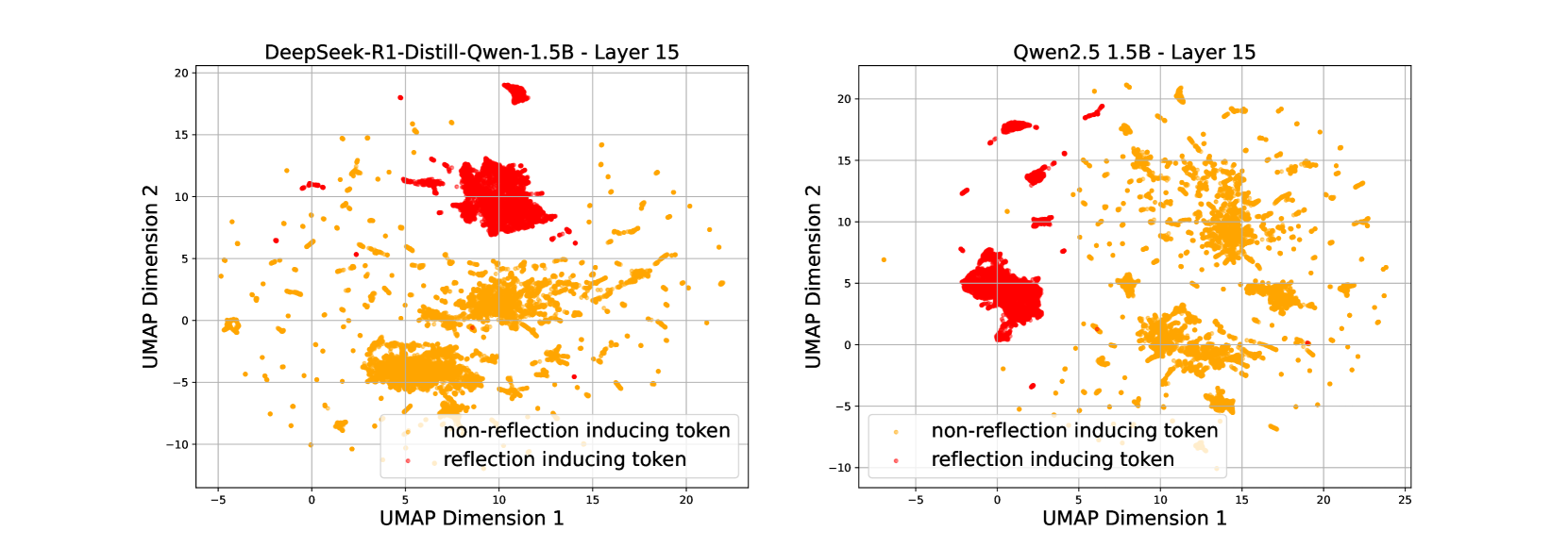
- Discovers that pretrained models already possess latent self-reflection capabilities (raising frequency from 0.6% to 18.6% via probing), debunking the idea that it is solely an RLVR artifact
- Identifies a linear direction in activation space (self-reflection vector) that separates reflective from non-reflective reasoning steps
- Demonstrates bidirectional control: enhancing this vector boosts accuracy on hard tasks, while suppressing it reduces token usage on easy tasks without hurting performance
Architecture

Illustration of the extraction of hidden states for 'reflection-inducing' vs. 'non-reflection-inducing' tokens.
Evaluation Highlights
- Enhancing the self-reflection vector improves reasoning accuracy by up to 12% on benchmarks like MATH500 and GSM8K
- Suppressing the self-reflection vector reduces output length by over 32% while maintaining performance on simpler tasks
- Reflection-inducing probing reveals pretrained Qwen2.5 has a latent reflection capacity of 18.6%, compared to a spontaneous rate of only 0.6%
Breakthrough Assessment
8/10
Significantly advances understanding of LLM reasoning by proving reflection is latent in pretraining, not just an RLVR artifact. Provides a practical, training-free mechanism to trade off accuracy vs. cost.