📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Synthetic Data Generation
Mathematical Reasoning
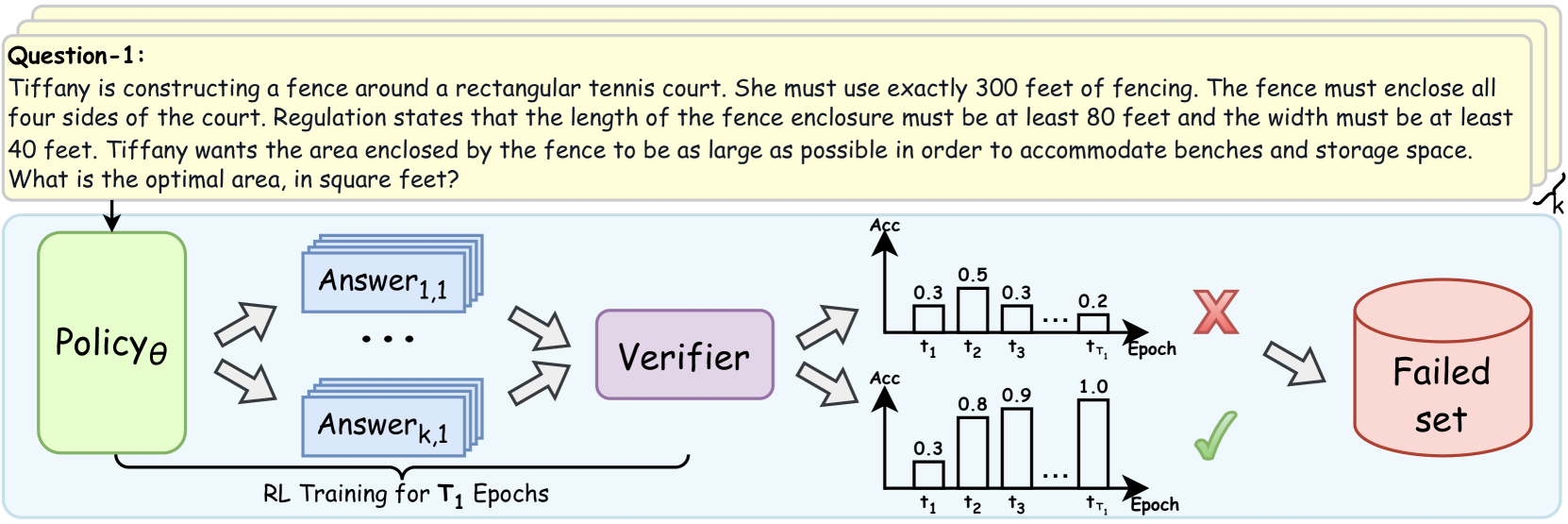
SwS improves LLM reasoning by using the model's own RL failure cases to identify weaknesses, then synthesizing targeted, difficulty-calibrated practice problems to address those specific deficiencies.
Core Problem
Existing RLVR datasets are scarce or unverified, and standard augmentation techniques (rephrasing/sampling) create problems that are either too easy (mastered) or too hard (unsolvable), leading to inefficient training due to vanishing gradients in group-relative policy optimization.
Why it matters:
- High-quality, verifiable math problems for RL are expensive to label manually.
- Training on problems the model already knows or consistently fails offers zero learning signal (advantage collapses to 0) in group-level RL algorithms like GRPO.
- Blindly expanding datasets without targeting model weaknesses leads to inefficient compute usage and suboptimal reasoning gains.
Concrete Example:
If a model consistently fails all geometry proofs involving 'circle theorems' (0% accuracy across RL epochs), standard augmentation might generate more algebra problems (which it already knows) or extremely hard calculus problems (which it can't solve). SwS detects the 'circle theorem' failure, extracts that concept, and synthesizes solvable geometry variants to specifically target that weakness.
Key Novelty
Self-aware Weakness-driven Problem Synthesis (SwS)
- Uses the policy model's own training trajectory to identify 'weaknesses'—problems where accuracy is consistently low or declining.
- Extracts core concepts from these failure cases and recombines them to synthesize new problems targeted at these specific weak areas.
- Allocates synthesis budget based on the failure rate of different categories and filters generated problems by difficulty to ensure they are learnable (neither trivial nor impossible).
Architecture
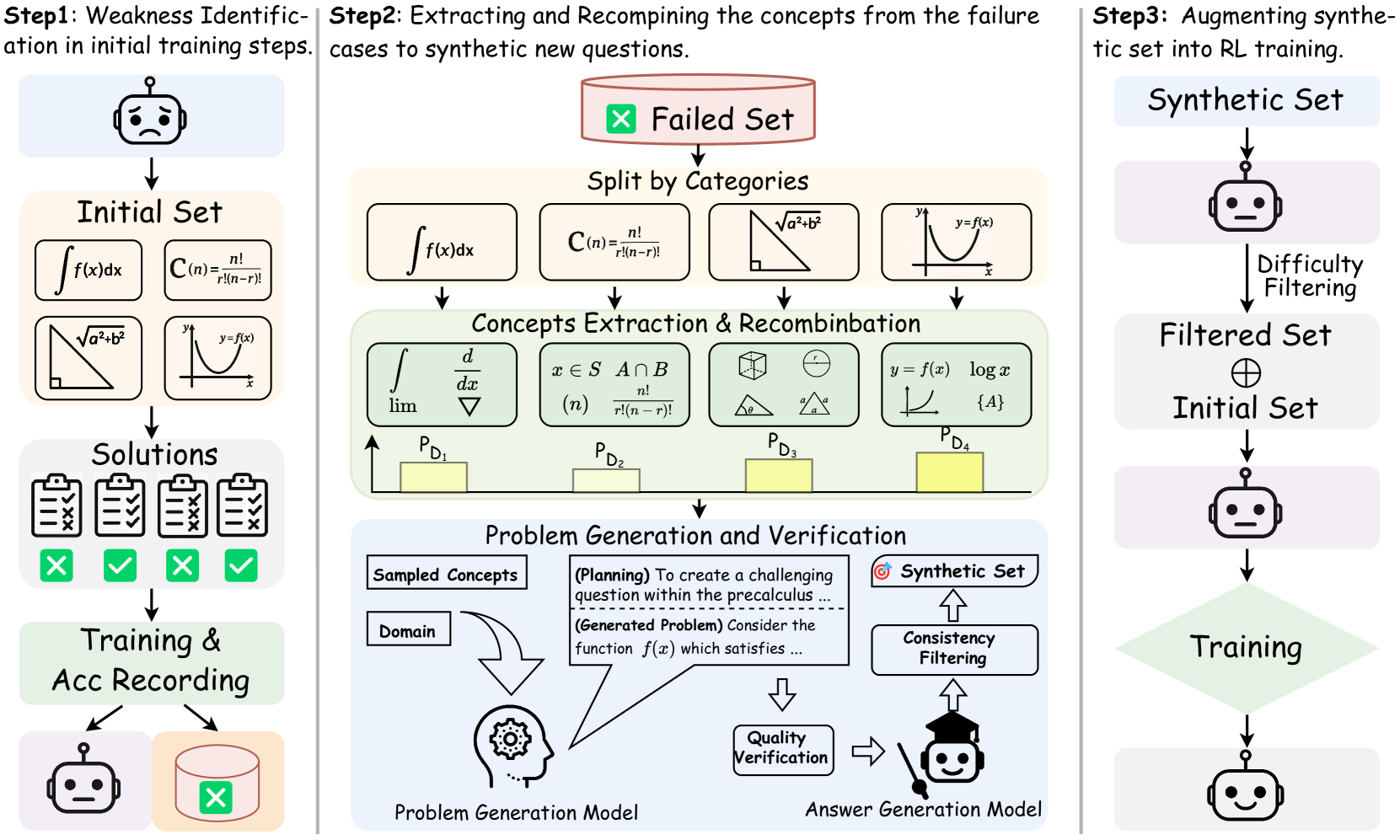
The SwS framework pipeline: (1) Self-aware Weakness Identification via preliminary RL, (2) Targeted Problem Synthesis using concept extraction, and (3) Augmented Training.
Evaluation Highlights
- Achieves average absolute improvement of +10.0% accuracy for the 7B model across eight mathematical reasoning benchmarks compared to the base model.
- Achieves average absolute improvement of +7.7% accuracy for the 32B model across eight benchmarks.
- Enables the model to solve up to 20.0% more previously failed problems in weak domains compared to training only on the original dataset.
Breakthrough Assessment
8/10
Strong empirical results (+7-10%) demonstrating that targeted synthetic data based on self-identified weaknesses is significantly more effective than general augmentation. Addresses a critical efficiency bottleneck in RLVR.