📝 Paper Summary
GUI Grounding (Graphical User Interface)
Vision-Language RL
InfiGUI-G1 improves GUI agent accuracy by forcing models to generate multiple diverse coordinate candidates during training, rewarded by a novel efficiency-based function that penalizes lazy, linear scanning.
Core Problem
Standard Reinforcement Learning with Verifiable Rewards (RLVR) suffers from a 'confidence trap,' where models repeatedly sample high-confidence but incorrect actions, failing to explore semantically correct alternatives.
Why it matters:
- Inefficient exploration bottlenecks 'semantic alignment,' preventing agents from associating abstract icons with their correct functions
- Current methods rely on Supervised Fine-Tuning (data-intensive/poor generalization) or standard RL (gets stuck in local optima), limiting reliability in complex, real-world GUIs
Concrete Example:
Given the instruction 'Use the camera to search,' a model might confidently click a generic 'Camera' icon. Standard RL keeps reinforcing this incorrect high-confidence action, never discovering the correct 'Google Lens' icon nearby because it rarely samples the tail of the probability distribution.
Key Novelty
Adaptive Exploration Policy Optimization (AEPO)
- Forces the model to output multiple coordinate guesses in a single pass (Multi-Answer Generation) to uncover correct actions hidden in the tail of the probability distribution
- Guides learning with an Adaptive Exploration Reward (AER) derived from efficiency principles (Utility/Cost), rewarding the model more for finding the correct answer early in its list of guesses
- Applies a 'quality-of-exploration' penalty if the generated points form a straight line (collinear), ensuring the agent explores the 2D space diversely rather than just scanning linearly
Architecture
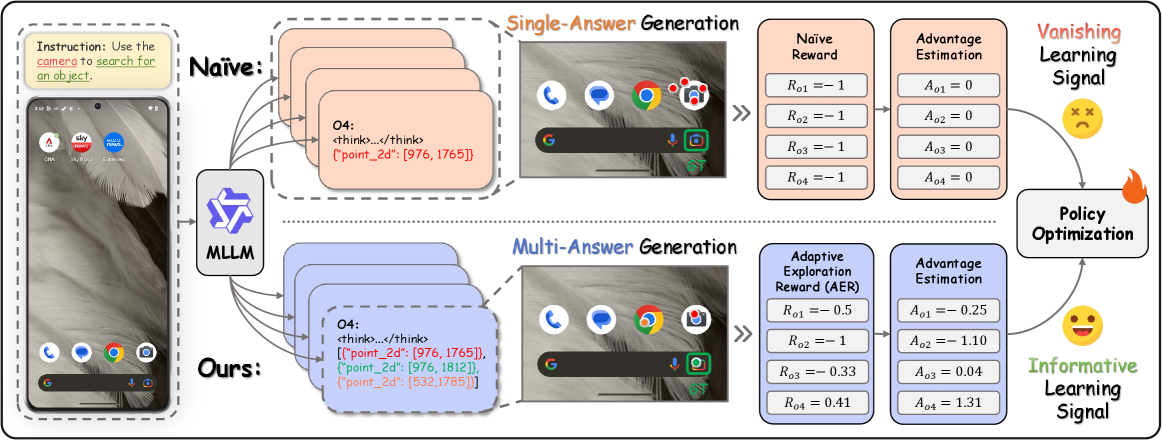
The Adaptive Exploration Policy Optimization (AEPO) framework workflow during training.
Evaluation Highlights
- Achieves up to 9.0% relative improvement against the Naive RLVR baseline on benchmarks testing generalization and semantic understanding
- Establishes new state-of-the-art results among open-source models (3B and 7B) on MMBench-GUI, ScreenSpot-Pro, and UI-Vision
- Demonstrates higher exploration success in a single pass (with ~2 answers) than a Naive RLVR baseline allowed 4 independent attempts (pass@4)
Breakthrough Assessment
8/10
Addresses a fundamental RL exploration problem in VLM agents with a theoretically grounded reward function. Significant gains on diverse benchmarks with modest model sizes (3B/7B).