📝 Paper Summary
Generative Reward Models
Chain-of-Thought Reasoning
Reinforcement Learning from Human Feedback
Mix-GRM optimizes reward models by dynamically synthesizing Breadth-CoT for subjective preferences and Depth-CoT for objective correctness, using RLVR to spontaneously switch between these mechanisms.
Core Problem
Current Generative Reward Models (GRMs) rely on unstructured length scaling of Chain-of-Thought (CoT), ignoring that different tasks require fundamentally different reasoning structures (parallel coverage vs. sequential rigor).
Why it matters:
- Scaling length indiscriminately does not guarantee performance; wrong reasoning types (e.g., breadth for math) can degrade objective correctness.
- Existing RMs struggle to provide reliable feedback for complex, diverse real-world queries ranging from creative writing to code generation.
Concrete Example:
In subjective tasks like creative writing, a model needs parallel exploration (Breadth) to cover tone and creativity. In objective tasks like math, it needs sequential verification (Depth). Using a single generic CoT style fails to capture these specific requirements.
Key Novelty
Mix-GRM (Synergistic Breadth and Depth for Generative Reward Models)
- Decomposes raw rationales into atomic 'Principle-Judgment-Verdict' units to enable modular synthesis of reasoning paths.
- Synthesizes two distinct CoT types: Breadth-CoT (parallel aggregation of principles) for subjective tasks and Depth-CoT (sequential reasoning-guided judgment) for objective tasks.
- Uses RLVR as a 'switching amplifier' that trains the model to automatically select the optimal reasoning style (Breadth or Depth) based on the task domain.
Architecture
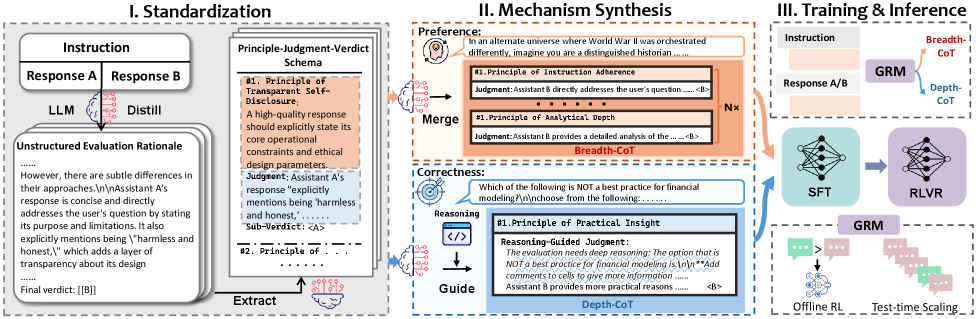
The three-stage framework of Mix-GRM: (I) Schema Standardization, (II) Mechanism Synthesis (B-CoT and D-CoT), and (III) Mechanism-Adaptive Alignment (SFT + RLVR).
Evaluation Highlights
- Achieves state-of-the-art performance (79.4 avg) on five general reward benchmarks, surpassing Skywork-Reward and FARE-8B.
- Outperforms RL-driven RM-R1-Instruct by 5.0 points (75.1 vs. 70.1) using only 9k SFT samples vs. massive RL exploration.
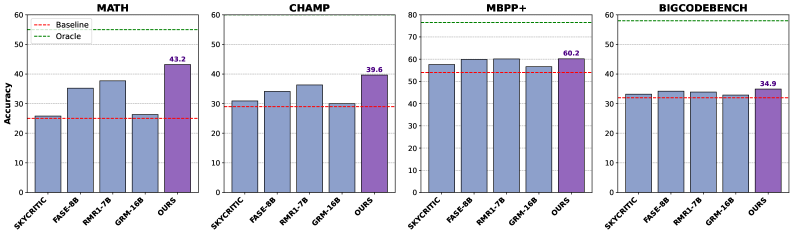
- Sets a new 8B-scale SOTA for Best-of-N reranking on MATH, achieving 43.2% accuracy compared to RM-R1's 37.7%.
Breakthrough Assessment
9/10
Introduces a fundamental structural distinction (Breadth vs. Depth) to reward modeling, moving beyond simple length scaling. Demonstrates that RL optimization acts as a mechanism switch, a significant insight for post-training.