📝 Paper Summary
Modularized RAG pipeline
Provence formulates context pruning as a sequence labeling task and unifies it with reranking into a single model, enabling efficient removal of irrelevant context sentences without computational overhead.
Core Problem
RAG systems suffer from computational overhead due to long contexts and hallucinations caused by irrelevant retrieved information, yet existing pruners are often inefficient, lack robustness across domains, or require fixed compression ratios.
Why it matters:
- Processing long contexts in LLMs increases latency and cost
- Irrelevant information in retrieved contexts can propagate into generated answers (hallucinations)
- Existing pruners often require heavy LLMs or separate inference steps, adding latency rather than reducing it
Concrete Example:
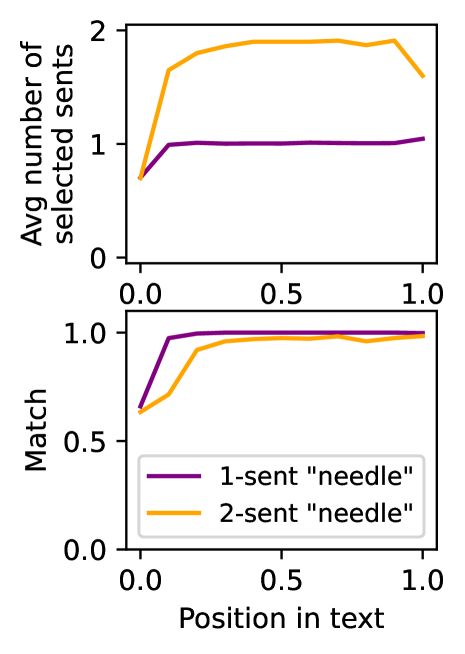
A retriever fetches 5 documents, but only 2 sentences in the 3rd document are relevant. Standard RAG feeds all 5 documents to the generator. Extractive baselines like RECOMP might pick a fixed top-k sentences, missing relevant info if k is too low or including noise if too high. Provence dynamically selects only the relevant sentences via a learned mask.
Key Novelty
Unified Reranking and Context Pruning (Provence)
- Formulates context pruning as a binary sequence labeling task (predicting a keep/discard mask per token) rather than autoregressive generation or ranking
- Unifies pruning with reranking by adding a pruning head to a cross-encoder reranker, allowing both tasks to share the same forward pass (zero-cost pruning)
- Trains on silver labels generated by a powerful LLM (Llama-3) that is instructed to answer questions while citing relevant sentences
Architecture
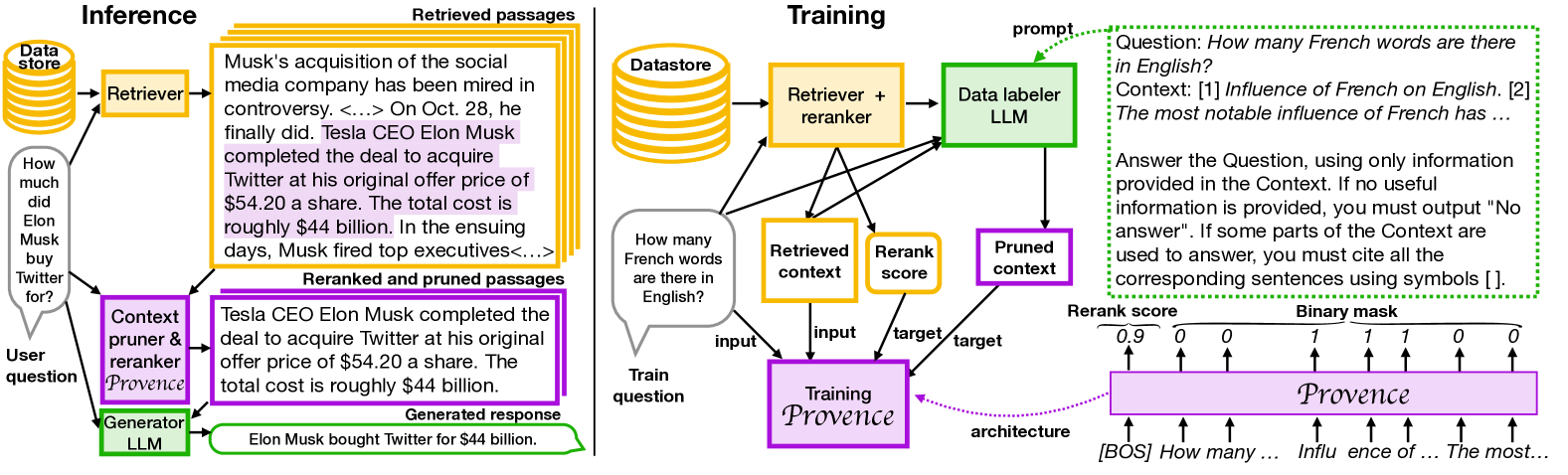
Overview of the Provence training and inference pipeline, contrasting the standalone pruner with the unified reranker+pruner.
Evaluation Highlights
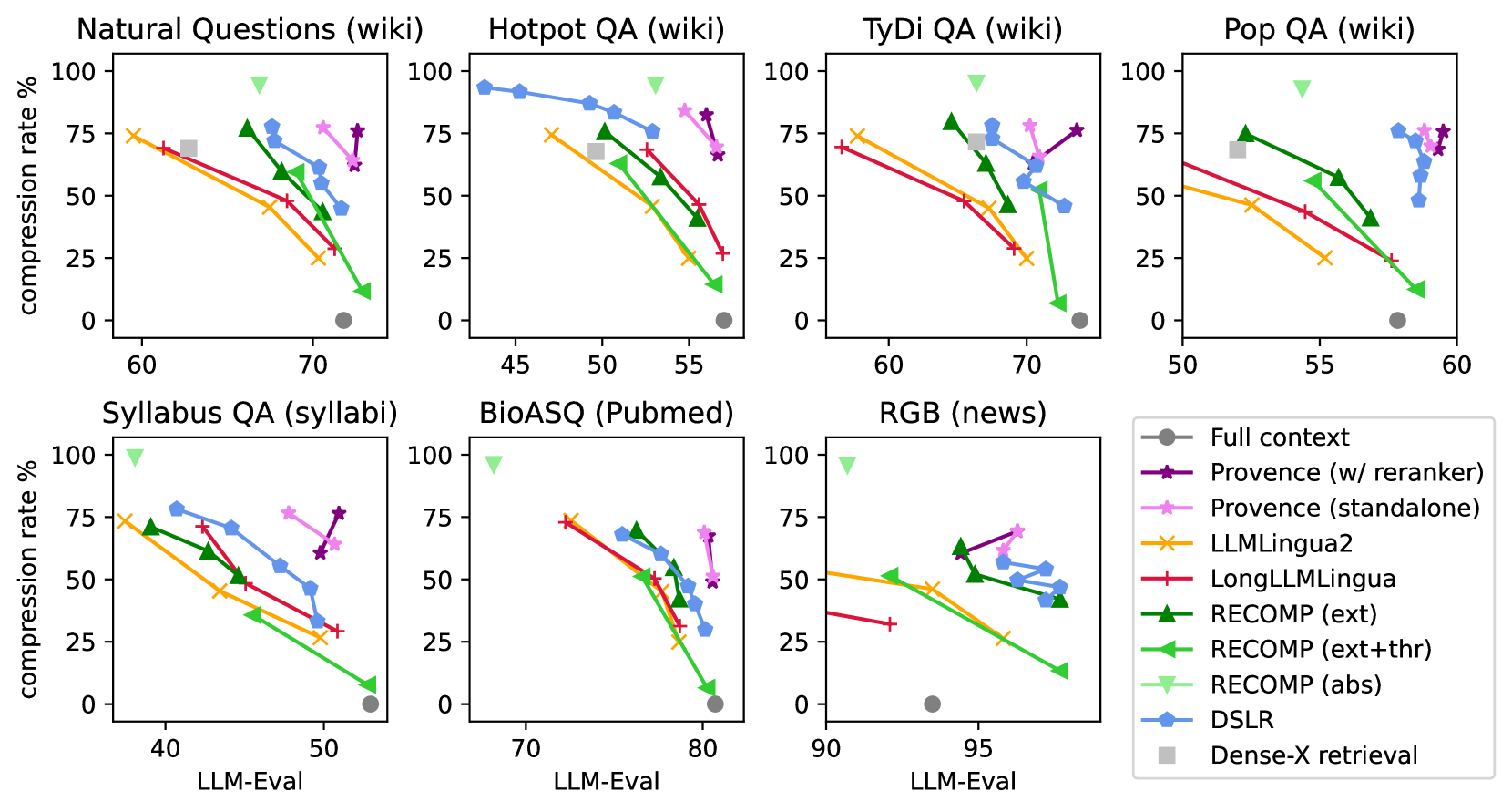
- Achieves negligible performance drop (or improvement) at ~50-80% compression rates across diverse domains (BioASQ, SyllabusQA, etc.)
- Outperforms LLMLingua2 and RECOMP baselines on the trade-off between compression and QA performance
- Unified model matches the reranking performance of the baseline DeBERTa-v3 reranker while adding pruning capabilities
Breakthrough Assessment
8/10
Highly practical contribution. Unifying pruning and reranking solves the efficiency bottleneck of separate pruning modules. Strong empirical results across diverse domains makes it immediately deployable.