📝 Paper Summary
Small Language Models (SLMs)
Reasoning Capability Enhancement
Reinforcement Learning with Verifiable Rewards (RLVR)
RED enhances small model reasoning by treating RL as a Recall phase and SFT as an Extend phase, dynamically balancing them via entropy changes and accuracy-aware policy shifts.
Core Problem
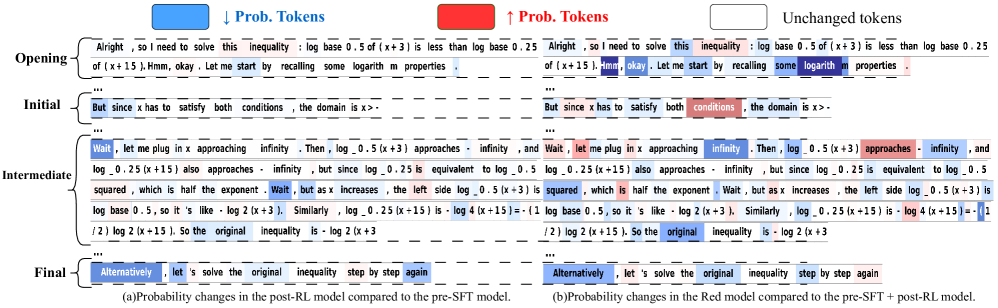
Small models trained via SFT distillation suffer from redundancy and overthinking, while standard RLVR lacks sufficient exploration space to discover new reasoning patterns on its own.
Why it matters:
- Small models (e.g., 1.5B) are computationally efficient but struggle to match the reasoning depth of larger models without effective distillation
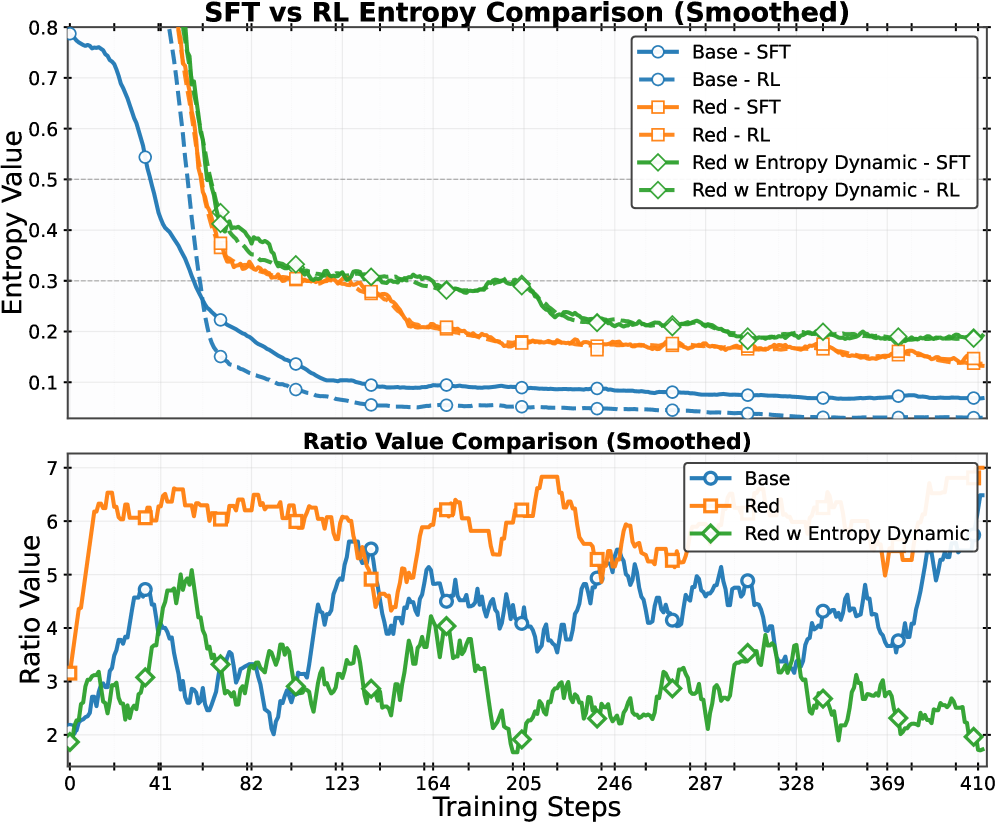
- Naive combinations of SFT and RL often lead to entropy collapse or performance degradation when offline data is forced into the policy
- Existing 'pre-SFT + post-RL' pipelines are inefficient, with long rollout times and diminishing returns on exploration
Concrete Example:
A small model trained only with SFT might produce correct answers but generate excessive 'overthinking' tokens (e.g., repeating 'Wait', 'Alternatively') that add no value. Conversely, pure RL might fail to solve hard problems because it cannot explore the solution space effectively without the 'guidance' of new knowledge from SFT data.
Key Novelty
Recall-Extend Dynamics (RED)
- Conceptualizes RLVR as 'Recall' (refining existing paths, reducing entropy) and SFT as 'Extend' (introducing new patterns, increasing entropy)
- Uses the ratio of entropy changes between RL and SFT to dynamically weight the contribution of offline SFT data during training
- Introduces an 'Accuracy-aware Policy Shift' that treats high-accuracy samples as on-policy (trusting the model) and low-accuracy samples as off-policy (imitating the teacher)
Architecture
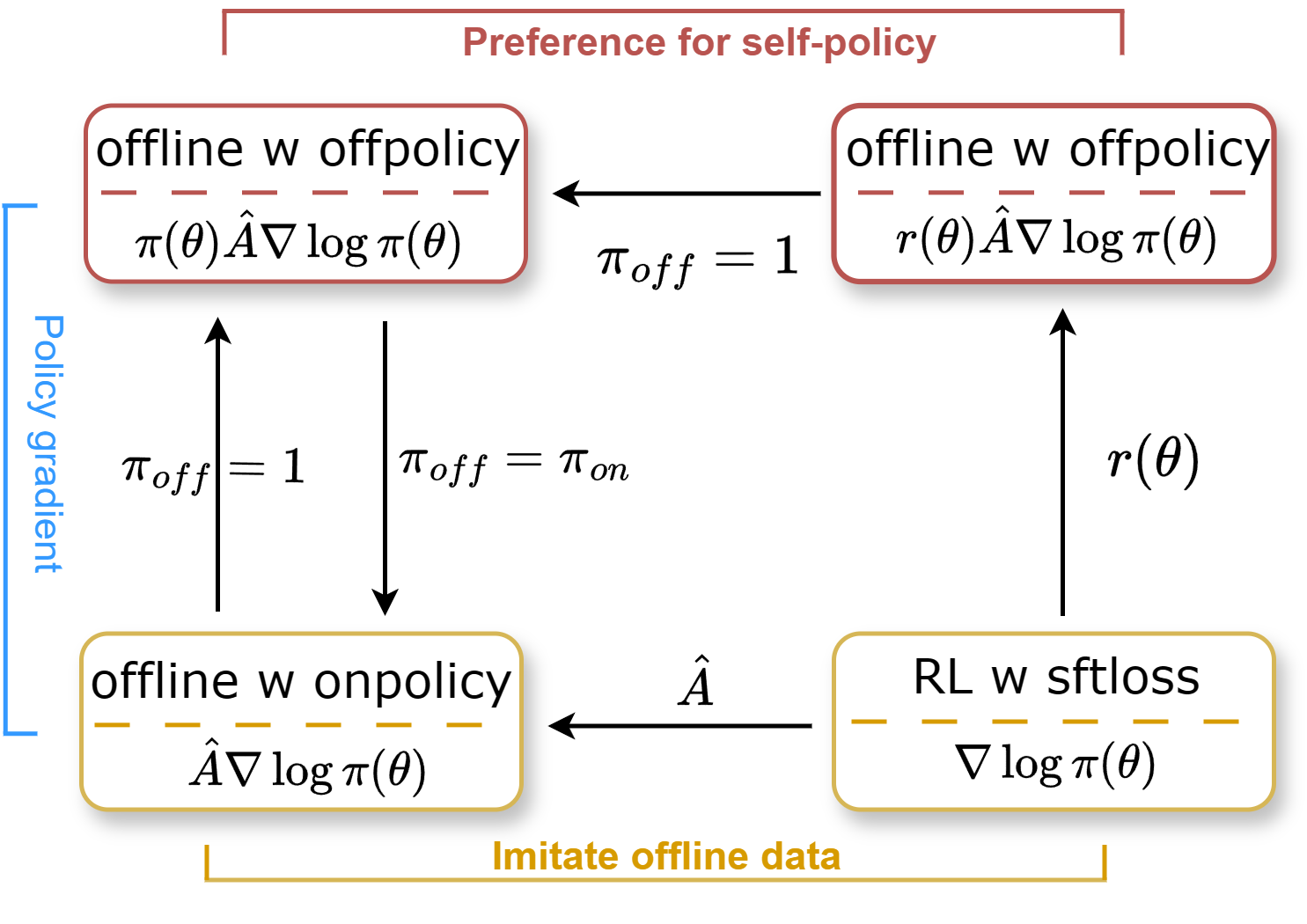
Conceptual diagram of the RED training framework showing the interplay between RLVR and Offline-SFT.
Evaluation Highlights
- Achieves 65.5% pass@1 on MATH500, outperforming the strong baseline LUFFY (63.8%) and Qwen2.5-Math-1.5B-Instruct (65.2%)
- Outperforms standard SFT+GRPO by +5.3% on MATH500 and +3.5% on AIME24
- Significantly reduces generation length to 2,050 tokens compared to >3,000 for baselines like ReLIFT, improving inference efficiency while maintaining accuracy
Breakthrough Assessment
7/10
Solid methodological improvement for small models. The dynamic entropy balancing is a clever heuristic for stabilizing RL+SFT, though the core idea is an evolutionary refinement of existing hybrid training rather than a radical paradigm shift.