📊 Experiments & Results
Evaluation Setup
Evaluation of reasoning robustness on math and logic tasks
Benchmarks:
- GSM8K (Grade School Math)
- MATH (Challenging Math Problems)
- MR-GSM8K (Diagnosability (identifying errors))
- RUPBench (Reasoning under perturbations)
Metrics:
- Recoverability Rate (correct answer given corrupted context)
- Diagnosability Score (correctly identifying error location)
- Pass@1 (Standard Clean Accuracy)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Recoverability results show GASP significantly outperforms baselines in solving problems given a corrupted partial chain-of-thought. | ||||
| Recoverability (GSM8K) | Success Rate | 45.0 | 72.0 | +27.0 |
| Recoverability (GSM8K) | Success Rate | 50.0 | 80.0 | +30.0 |
| Diagnosability results demonstrate improved ability to detect errors in provided solutions. | ||||
| MR-GSM8K | F1 / Accuracy | 20.0 | 62.0 | +42.0 |
| Clean accuracy is maintained or improved, unlike methods that trade off clean performance for robustness. | ||||
| GSM8K | Pass@1 | 78.0 | 81.0 | +3.0 |
Experiment Figures
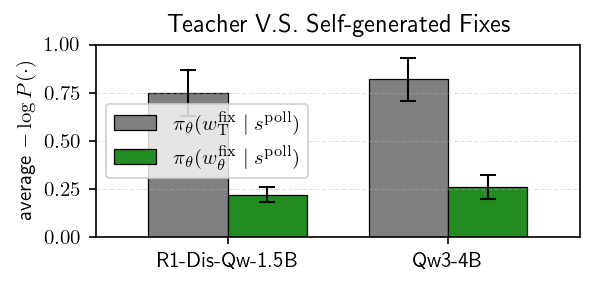
Comparison of likelihoods for self-generated repairs vs. teacher-generated repairs under the polluted context.
Main Takeaways
- Adversarial self-play creates an effective curriculum: as the agent improves, the polluter generates subtler bugs, driving further agent improvement.
- In-distribution guidance is critical: simply training on outcomes fails because recoveries are too rare early in training.
- Robustness transfers: Training on self-generated corruptions improves performance on external benchmarks like RUPBench and MR-GSM8K.
- GASP reverses the 'inverse scaling' trend where larger models are more easily misled by context.