📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Generative Reward Modeling
Creative Writing
Writing-Zero enables effective reinforcement learning for subjective writing tasks by combining a pairwise generative reward model with a bootstrapped algorithm that uses self-generated responses as dynamic references.
Core Problem
Non-verifiable tasks like creative writing lack objective ground-truth answers, forcing reliance on scalar reward models that are prone to reward hacking and poor generalization.
Why it matters:
- Standard RLHF often leads to 'length bias' where models generate verbose, vacuous content just to satisfy the reward model
- Current RLVR success is limited to math/code; extending it to subjective domains is necessary for comprehensive LLM development
- Scalar reward models fail to capture nuanced human preferences compared to comparative/pairwise assessments
Concrete Example:
In creative writing, models trained with standard scalar rewards often exhibit 'over-explanation,' appending lengthy, redundant justifications of how they met user requirements to the end of a response, even when the actual content is poor.
Key Novelty
Writing-Zero (GenRM + BRPO)
- Use a Pairwise Generative Reward Model (GenRM) that produces text critiques and scores for response pairs, converting subjective quality into pseudo-verifiable binary signals
- Introduce Bootstrapped Relative Policy Optimization (BRPO), where the model compares its outputs against a randomly selected 'peer' from the same batch (bootstrap) rather than a fixed external baseline
Architecture
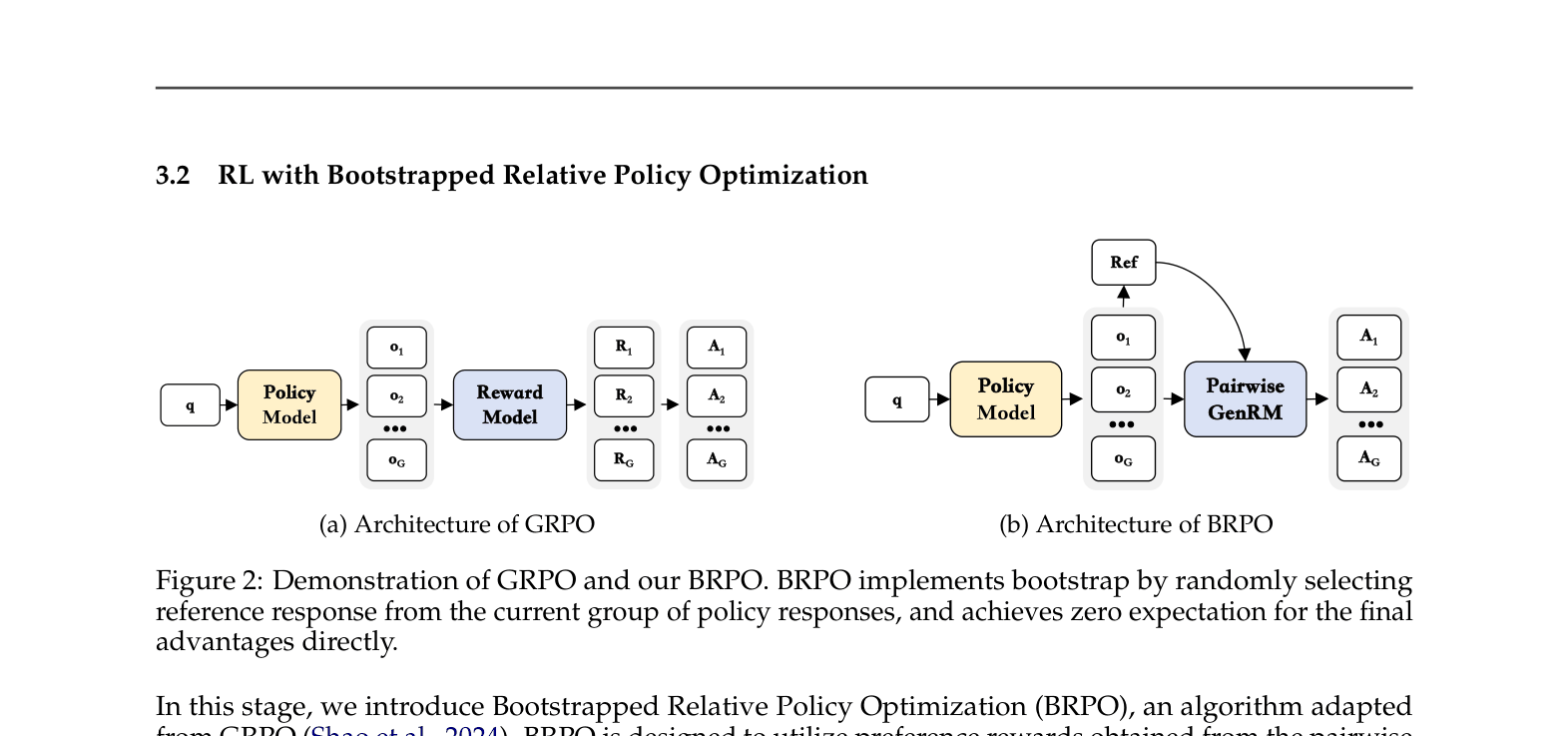
Comparison of GRPO (Group Relative Policy Optimization) and BRPO (Bootstrapped Relative Policy Optimization) architectures.
Evaluation Highlights
- Writing-Zero improves base model performance on WritingBench from 6.89 to 8.29, without supervised fine-tuning
- Reduces reward hacking significantly: 'mean explanation length' drops from 417 tokens (scalar reward baseline) to 58 tokens (Writing-Zero)
- The Pairwise Writing GenRM outperforms Claude-3.5-Sonnet on RewardBench (87.4% vs 84.2%) despite being trained primarily on Chinese data
Breakthrough Assessment
8/10
Successfully extends the 'Zero' (pure RL) paradigm from reasoning to creative writing. The bootstrap mechanism for relative policy optimization is a clever solution to the lack of ground truth.