📝 Paper Summary
Mechanistic Interpretability
LLM Reasoning
Model Selection
A model's reasoning potential is determined by its intrinsic, pre-trained ability to distinguish sound logical rules from noise, which can be quantified microscopically via the Soundness-Aware Level (SAL).
Core Problem
Reinforcement Learning with Verifiable Rewards (RLVR) improves reasoning, but its effectiveness varies drastically across different base models, and we lack a systematic way to predict which pre-trained models will become strong reasoners.
Why it matters:
- Applying RLVR to the wrong base model wastes massive computational resources if the model lacks the intrinsic potential to reason
- Current methods analyze macroscopic behaviors (output text) rather than the internal mechanisms driving reasoning capabilities
- Understanding the microscopic determinants of reasoning helps in selecting and designing better base models for the next generation of reasoning systems
Concrete Example:
When applying the exact same RLVR pipeline, Qwen-2.5-7B develops strong reasoning capabilities, while Llama-3.1-8B lags behind. Macroscopic analysis of their pre-training text doesn't explain this gap, but microscopic analysis shows Llama treats spurious correlations with the same high confidence as strict mathematical rules.
Key Novelty
Soundness-Aware Level (SAL) via Logic-SAEs
- Formalizes internal model computation as 'Horn clauses' (if-then rules) between features extracted by Cross-Layer Sparse Autoencoders (SAEs)
- Measures the divergence (JSD) between the model's internal confidence distributions for 'Strict' rules versus 'Noise' rules
- Establishes a precise empirical law linking this internal microscopic signature directly to macroscopic post-RLVR error rates
Architecture
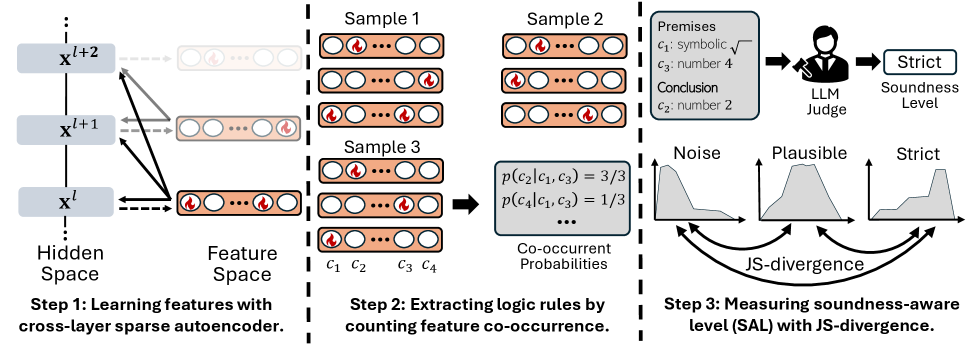
The workflow for calculating Soundness-Aware Level (SAL). Steps: (1) Extract features with SAE, (2) Estimate rules via co-occurrence, (3) Judge soundness with LLM, (4) Compute SAL via divergence.
Evaluation Highlights
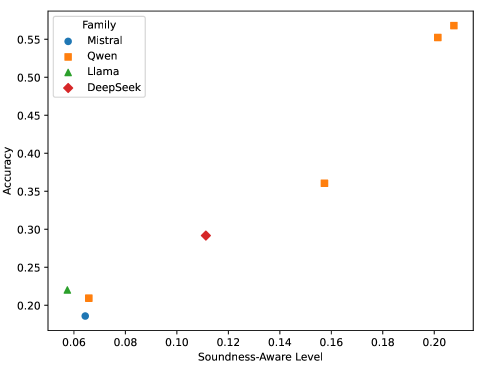
- SAL predicts post-RLVR error rates with high fidelity (R^2 = 0.87) across unseen models from diverse families (Qwen, Mistral, Llama, DeepSeek)
- Qwen-2.5-7B achieves a high SAL of ~0.20 (strong separation of sound/unsound rules), while Llama-3.1-8B scores ~0.06 (soundness-agnostic)
- The predictive law holds across model scales, with SAL increasing monotonically from 0.5B to 14B parameters within the Qwen family
Breakthrough Assessment
9/10
Establishes a quantitative law connecting microscopic mechanism interpretability (SAE features) directly to downstream macroscopic capability (reasoning potential), a rare and significant bridge in AI science.