📝 Paper Summary
Reinforcement Learning with Verifiable Rewards (RLVR)
Math Reasoning
Curriculum Learning
This paper proposes a dynamic filtering method for reinforcement learning that selectively trains on math problems with intermediate pass rates, theoretically proving these samples maximize the learning signal.
Core Problem
In reinforcement learning with verifiable rewards (like math), training is inefficient because many samples are either trivially easy (always correct) or impossibly hard (always incorrect), providing zero gradient variance and no learning signal.
Why it matters:
- Training Large Language Models (LLMs) with Reinforcement Learning (RL) is computationally expensive, making sample efficiency critical.
- Existing difficulty filtering methods often rely on static, offline proxies that do not adapt to the model's changing capabilities during training.
- The 'Zone of Proximal Development' theory suggests learning is optimal at intermediate difficulty, but standard RL algorithms do not natively enforce this data selection.
Concrete Example:
If a model attempts a math problem and gets it right 0% of the time (too hard) or 100% of the time (too easy), the variance of the reward is zero. In GRPO, this results in an advantage of zero, meaning the model performs a computation rollout but receives no gradient update to improve its policy.
Key Novelty
Online Difficulty Filtering with Variance-Based Theoretical Bound
- Identifies that the reward variance (pass rate variance) is the theoretical lower bound of the expected policy improvement (reverse KL divergence), validating that samples with ~50% pass rate are most valuable.
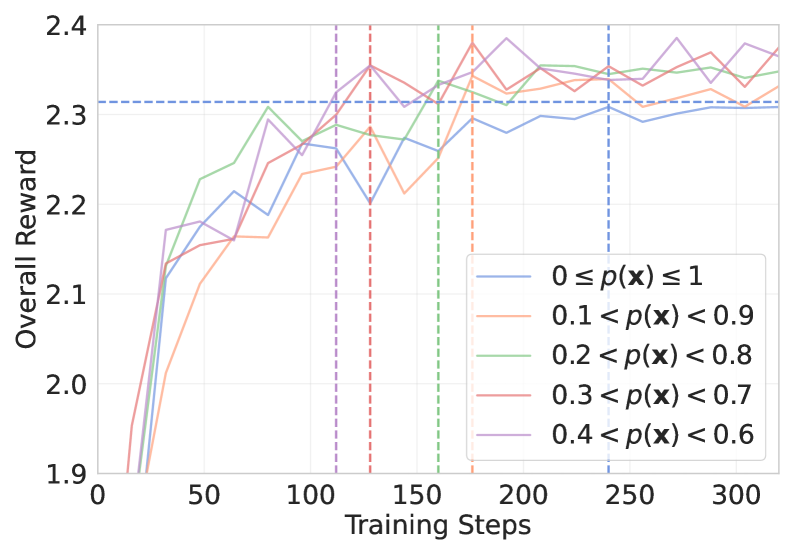
- Implements a dynamic filtering mechanism that assesses problem difficulty 'on the fly' using the current policy's rollouts, discarding items outside a target difficulty range (e.g., 0.2–0.8 pass rate).
- Uses an asynchronous sampling strategy to replace filtered-out easy/hard items with new rollouts immediately, ensuring a fixed training batch size without instability.
Architecture
The Online Difficulty Filtering workflow integrated into the GRPO training loop.
Evaluation Highlights
- Achieves +12% pass@1 improvement on the AMC math benchmark using a 7B model compared to standard GRPO.
- Achieves +10% pass@1 improvement on the AIME benchmark using a 3B model compared to standard GRPO.
- Attains optimal performance in less than half the gradient update steps required by standard GRPO, significantly improving sample efficiency.
Breakthrough Assessment
7/10
Provides a solid theoretical justification for difficulty filtering in RLVR and empirically demonstrates significant efficiency gains. While the core concept of curriculum learning is known, the specific application to online RLVR with variance-based bounds is a valuable contribution.